
CSAPP U8 筆記與(部分)練習題解答
異常
假設程序計數器每次執行代碼的值會組成一個序列$
異常(exception) 就是控制流中的突變,用來響應處理器中的某些變化。
當處理器檢測到事件(event) 發生,它會通過異常表(exception table) 間接調用異常處理程序(exception handler)。當異常處理程序完成後,會發生以下情況之一:
- 返回到事件發生時運行的指令。
- 返回到事件發生時運行的下一條指令。
- 終止程序。
異常處理
異常表的起始地址被存放於異常表基址寄存器(exception table base register) 的特殊CPU寄存器中。而系統中每種類型的異常都分配了唯一的異常號(exception number),我們可以通過以下算法由異常號訪問異常表:
異常類似於過程調用,但有不同:
- 把額外的處理器狀態壓入棧。
- 若控制從用戶程序轉到內核,則把項目壓到內核棧中而非用戶棧。
- 異常處理程序運行在內核模式下,對系統資源有完全的訪問權限。
異常的類別
| 類別 | 原因 | 異步/同步 | 返回行為 |
|---|---|---|---|
| 中斷 interrupt | 來自I/O設備的信號 | 異步 | 總是返回到下一條指令 |
| 陷阱 trap | 有意的異常 | 同步 | 總是返回到下一條指令 |
| 故障 fault | 潛在可恢復的錯誤 | 同步 | 可能返回到當前指令 |
| 終止 abort | 不可恢復的錯誤 | 同步 | 不返回 |
中斷
中斷是異步發生的,來自I/O設備信號。硬件中斷不是由指令造成的,所以稱為異步。硬件中斷的處理程序常稱中斷處理程序(interrput handler)。
IO設備,例如磁盤控制器,通過向CPU芯片的引腳發送信號,並將異常號放到系統總線上來觸發中斷。此異常號標記了引起中斷的設備。
CPU發現中斷引腳的電壓變高,就會存系統總線讀取異常號,然後調用處理程序。處理程序返回後,將控制傳遞給下一條指令,就像中斷沒有發生過一樣。
剩下的異常類型為同步發生,是執行當前指令的結果。我們稱這類指令故障指令(faulting instruction)。
陷阱和系統調用
當用戶程序需要向內核請求系統調用時,會故意觸發陷阱。
CPU提供syscall n指令,當程序請求服務$n$時,syscall會導致陷阱。此時異常處理程序會解析程序參數並調用內核程序。
故障
故障由錯誤引起,若故障處理程序可以修正這個錯誤,就會將控制返回到引起故障的指令並重新執行它。否則,返回到內核的abort例程,abort例程會終止引起故障的程序。
終止
終止是不可恢復的致命錯誤造成的結果,通常是硬件錯誤。比如RAM損壞。終止處理程序不會將控制返回應用程序,而是返回到abort例程。
Linux/x86-64 系統中的異常
Linux有256種異常,其中0~31由Intel定義,對所有x86-64系統皆相同。
| 異常號 | 描述 | 異常類別 |
|---|---|---|
| 0 | 除法錯誤 | 故障 |
| 13 | 一般保護故障 | 故障 |
| 14 | 缺頁 | 故障 |
| 18 | 機器檢查 | 終止 |
| 32~255 | 操作系統定義的異常 | 中斷或陷阱 |
若代碼嘗試除以零就會觸發除法錯誤。Unix會直接終止程序,而Linux Shell會將錯誤報告為浮點異常(Floating exception)。
若程序引用未定義的虛擬內存區域,或試圖寫只讀的文本段等行為會觸發一般補戶故障。Linux不會嘗試修復這種故障。Linux shell會將這種故障報告為段故障(Segmentation fault)。
缺頁是會重新執行故障指令的一個示例。
當執行故障指令時發現致命的硬件錯誤會導致機器檢查。處理程序不會返回控制給應用程序。
在x86-64系統上,系統調用通過syscall陷阱指令實現。所有Linux系統調用的參數都是由寄存器傳遞而非棧。%rax包含系統調用號,%rdi, %rsi, %rdx, %r10, %r8, %r9共包含六個參數。
當調用返回時,%rcx, %r11會被破壞,而%rax包含返回值。
進程
進程:執行中程序的實例。
進程提供給程序:
- 獨立的邏輯控制流
- 私有的地址空間
邏輯控制流
進程輪流使用處理器,每個進程執行一部份邏輯流,然後被搶占(preempted) 暫時掛起,輪到其他進程運行。
並發流
並發流(concurrent flow):一個邏輯流的執行時間與另一個流重疊。
並行流(parallel flow):兩個流並發的運行在不同處理器核中。
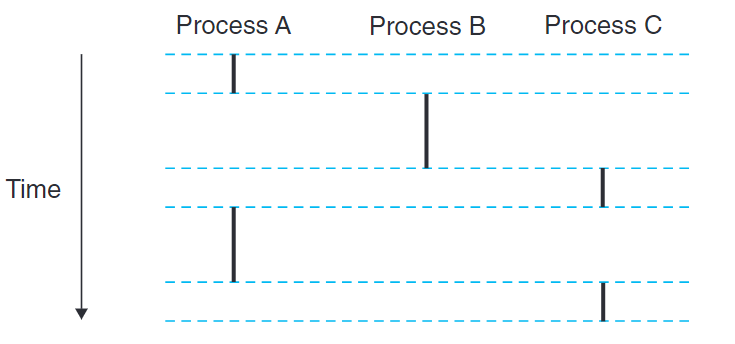
如上圖,A和B並發,也和C並發。但是B和C不並發,因為當C開始執行時,B已經執行結束。
一個進程執行其部分控制流的時間段稱時間片(time slice),一個進程與其他進程輪流運行的概念稱多任務(multitasking),亦稱為時間分片(time slicing)。
練習題
8.1
| 進程對 | 並發的? |
|---|---|
| AB | y |
| AC | n |
| BC | y |
用戶模式與內核模式
處理器使用某個控制寄存器中的模式位(mode bit) 的設置與否來判斷進程是否處於內核模式中。
進程從用戶模式轉為內核模式的方法只有通過中斷、故障或系統調用這些異常。異常發生時,控制傳遞到EH,此時由用戶模式切換為內核模式。當EH結束後,切換回用戶模式後返回控制給程序。
上下文切換
調度器(scheduler) 可以搶佔當前進程,利用上下文切換(context switch) 機制重新開始另一個被搶占的進程。
上下文切換:
- 保存當前進程上下文。
- 恢復某個被搶佔進程的上下文。
- 將控制傳遞給新恢復的進程。
內核執行系統調用時,可能發生上下文切換。若系統調用因某事件阻塞,內核便可執行上下文切換。例如,read系統調用訪問磁盤,為了等待數據讀取,內核執行上下文切換運行另一個進程。
中斷也可能造成上下文切換。比如,系統有一種產生週期性定時器中斷的機制,通常每1或10ms發生一次。此時,內核會判定當前進程執行得夠久了,切換到新進程執行。
系統調用錯誤處理
當Unix風格的函數遇到錯誤,通常會返回-1,並設置全局整數變量errno。
當Posix與GAI風格的函數遇到錯誤,會將錯誤代碼作為返回值。
我們如下包裝三種不同風格的異常處理:
1 | void unix_error(char *msg) |
錯誤處理包裝函數可以簡化異常處理的代碼,對於一個基本函數foo我們定義一個相同參數與返回的包裝函數Foo,注意,第一個字母轉成大寫。
當我們想為系統函數定義錯誤處理包裝函數時,可以如下編寫:
1 | pid_t Wait(int *status) |
進程控制
獲取PID
使用函數getpid()或gitppid()。
進程創建與終止
當進程停止 時,處於被掛起(suspended) 的狀態,不會被調度。當收到信號SIGSTOP, SIGTSTP, SIGTTIN, STGTTOU時進程停止,直到收到信號SIGCONT才會繼續運行。
exit(int status)以status退出狀態來終止進程
父進程調用pid_t fork()函數創建子進程。返回值:子進程返回0,父進程返回子進程PID。
子進程與父進程幾乎相同,也擁有父進程打開的文件,唯一的區別就是PID不同。且父子進程並發執行。
二者的地址空間相同,但是獨立。也就是說,子進程修改自己的內存數據不會更改父進程的數據。
注意,若代碼中調用兩次fork()會創建3個進程,因為被父進程創建的子進程也會調用一次fork()。
練習題
8.2
A. p1: x=2 \n p2: x=1
B. p2: x=0
回收子進程
當子進程終止時,內核不會馬上把它從系統中清除,而需等待父進程回收(reaped),此時子進程稱僵死進程(zombie)。當父進程回收子進程時,內核將子進程的退出狀態傳遞給父進程,然後拋棄已終止的子進程。
若父進程終止,但還未回收其子進程,系統會安排init進程(PID始終為1)回收。注意,我們總應該回收僵死進程,因為就算沒有在運行,它們也會占用內存資源。
我們可以調用pid_t waitpid(pid_t pid, int *statusp, int opitons)等待子進程終止或停止。返回:若成功為子進程PID,若設置WNOHANG且任何子進程都未終止則為0,若有其他錯誤則為-1。
默認情況(option=0),waitpid掛起調用進程的執行,直到等待集合(wait set) 的其中一個子進程終止。
- 判定等待集合的成員
當pid > 0,等待集合為PID所指定的單獨子進程。
當pid = -1,等待集合由父進程的所有子進程組成。 - 修改默認行為
通過將option修改為以下幾項常數可以修改默認行為:
WNOHANG:若等待集合中沒有任何子進程終止,立即返回。若想在等待子進程終止時做其他工作可用。
WUNTRACED:返回PID的值比默認多一個,返回已終止或被停止子進程的PID。
WCONTINUED:掛起調用進程,直到等待集合有子進程終止或被終止的進程收到SIGCONT。 - 檢查已回收子進程的退出狀態
我們可以檢查pstatus指向的status檢查退出狀態。 wait函數
pid_t wait(int *statusp)函數是waitpid的簡化版本。
調用wait(&status)等價於waitpid(-1, &status, 0)。
練習題
8.3
acbc
abcc
bacc
8.4
A. 6
B.
Hello
0 // from father
1 // from son
Bye // from son and exit with status 2
2
Bye
讓進程休眠
unsinged int sleep(unsinged int secs)讓進程掛起secs秒。返回:若請求的時間到了則返回0,否則返回還要掛起多久(發生在sleep被信號打斷)。
int pause()讓函數休眠直到收到信號。該函數總是返回-1。
練習題
8.5
1 | unsigned int snooze(unsigned int secs) |
加載並運行程序
int execve(const char *filename, const char *argv[], const char *envp[])可以在當前上下文中加載運行一個程序,其中argv是參數列表,envp是環境變量列表。
execve只有出現錯誤才會返回,其餘情況從不返回。
execve加載filename後,調用啟動代碼設置棧,將控制傳遞給新程序的主函數。
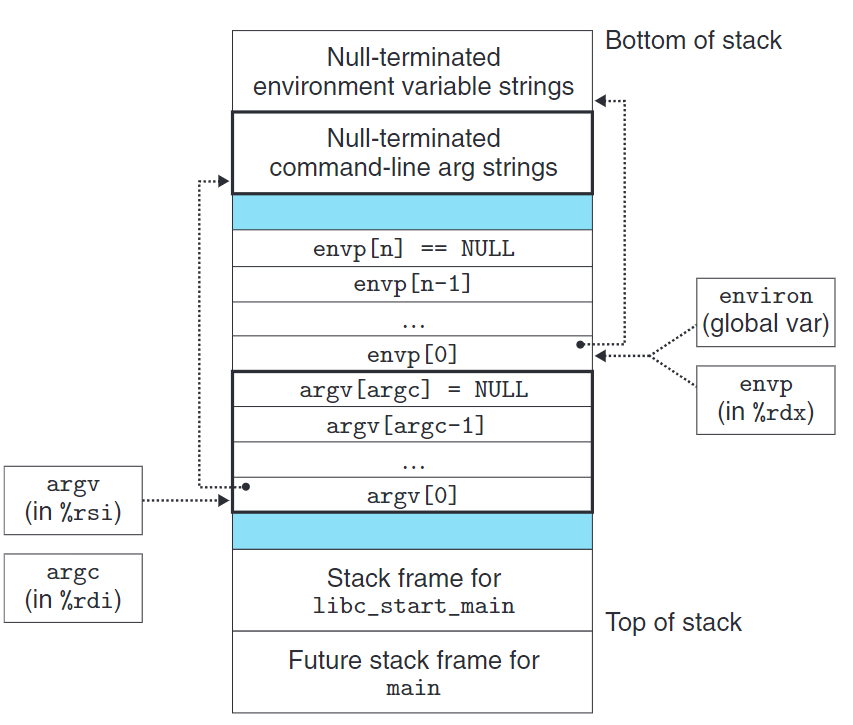
上圖是main開始執行時棧的結構。
char *getenv(const char *name)在環境數組中搜索字符串”name=value”,若找到則返回value,否則返回NULL。
若環境數組包含如”name=oldvalue”的字符串,則:
int setenv(const char *name, const char *newvalue, int overwrite)在overwrite非零時使用newvalue替代oldvalue。若name不存在,則把”name=newvalue”添加到數組中。void unsetenv(const char *name)刪除環境數組中匹配項。
練習題
8.6
1 | /* myecho.c */ |
注意,%2d表示輸出兩位整數,不足兩位在左側補空格。
循環可以使用以下代碼替代。
1 | for (i = 0; envp[i] != NULL; i++) |
信號
Linux信號是軟件形式的異常,允許進程和內核中斷其他進程。一個信號就是一條通知進程系統發生某類型事件的消息。
硬件異常由內核EH處理,通常對用戶進程不可見。信號這種機制則通知用戶進程發生了這些異常。
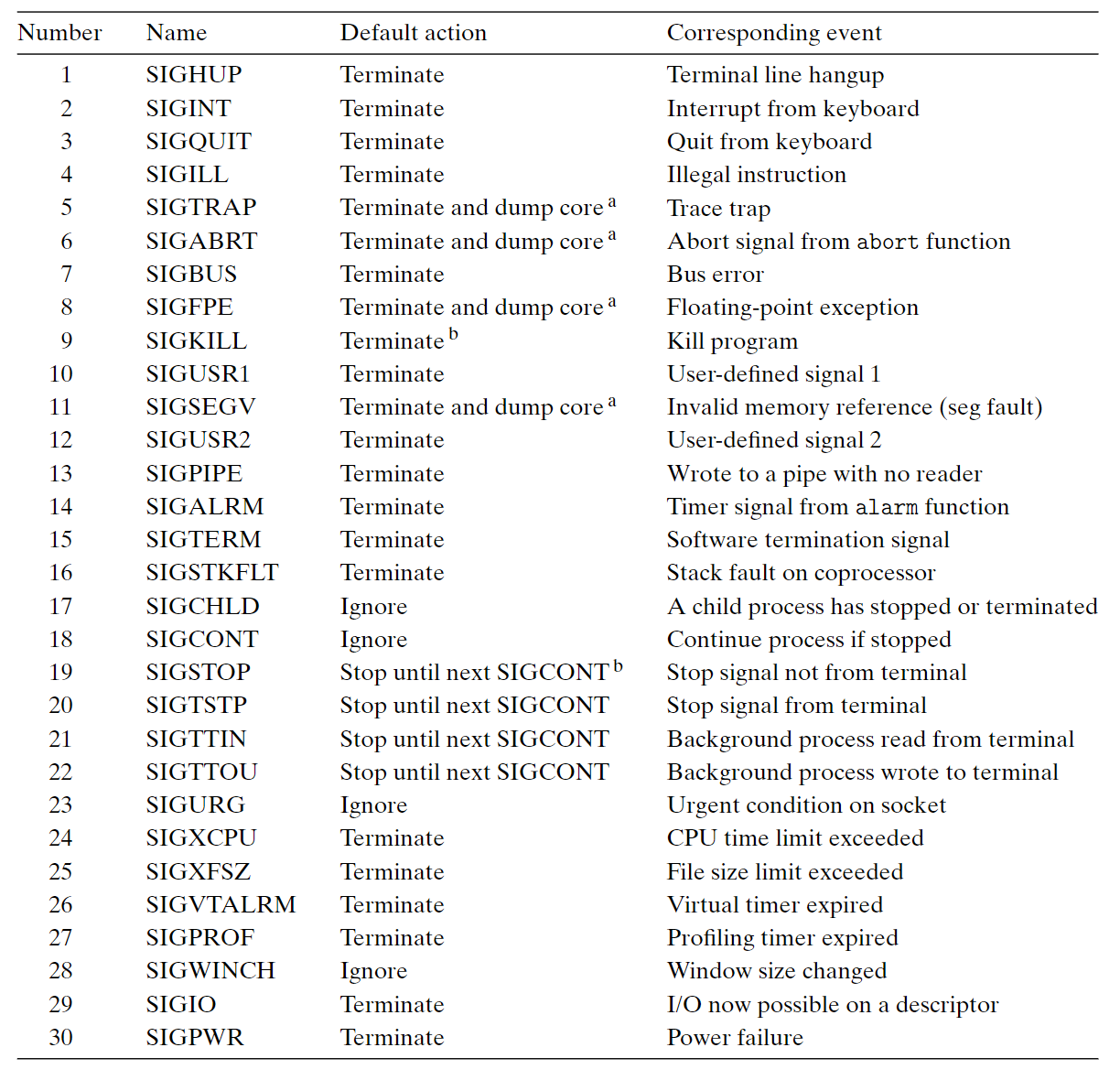
b. 這個信號不能被捕獲與忽略。 ↩
信號術語
傳遞信號到進程分為兩個步驟(進程可以發送信號給自身):
- 發送信號
發送信號有以下原因:- 內核檢測到系統事件,如除零或子進程終止。
- 進程調用
kill顯式地要求內核發送信號給目的進程。
- 接受信號
目的進程被內核強迫對信號做出反應,此時目標進程接受信號。
進程可以忽略、終止或運行一個用戶層函數,稱信號處理程序(signal handler) 來捕獲信號。
一個發出而還未被接收的信號稱待處理信號(pending signal)。無論何時一種類型只能有一個待處理信號。
進程可以選擇信阻塞接收某種信號。此時,被阻塞的信號仍可以發送,但是產生的待處理信號不會被接收,直到取消阻塞。
內核為每個進程維護待處理信號集合,存放於pending位向量中。只要傳送一個類型k的信號,pending的第k位就會被設置。當接受類型為k的信號,就會清除第k位。
被阻塞的信號集合存放於blocked位向量中。
發送信號
進程組
每個進程都僅屬於一個進程組(process group),進程組由進程組ID標識。
我們可以使用pid_t getpgrp()取得當前進程所屬的進程組ID。
默認情況下,子進程會與其父進程屬於同一進程組。
我們可以使用int setpgid(pid_t pid, pid_t pgid),若pid為0則使用當前進程PID,若pgid為0則使用pid作為進程組ID。
使用/bin/kill發送信號
1 | /bin/kill -9 15213 |
上指令將信號9(SIGKILL)發送給進程15213。
若指定的PID為負,則信號會傳送給該進程所屬進程組的每個進程。
從鍵盤發送信號
Unix shell 使用作業(job) 這種概念表示解析一條命令而創建的進程。無論何時至多只能有一個前台作業。
比如:
1 | ls | sort |
上述代碼會創建一個包含兩個進程的前台作業,兩個進程之間由 Unix 管道連接。
shell 會為每個作業創建獨立的進程組,通常選擇作業中的父進程PID作為進程組ID。
使用ctrl + c會使內核發送SIGINT到前台進程組中的每個進程。使用ctrl + z會發送SIGSTP到前台進程組,導致掛起前台作業。
用kill函數發送信號
使用int kill(pid_t pid, int sig)可以發送信號。若pid大於0,則直接發送信號給進程pid。若等於0,則發送信號給當前進程所屬的進程組中的所有進程(包括自身)。若小於0,則發送給進程組|pid|中的每個進程。
用alarm函數發送信號
進程通過unsigned int alarm(unsigned int secs)在secs秒後,向自身發送SIGALRM信號。
一旦調用alarm函數,就會取消任何待處理的鬧鐘,並返回該鬧鐘在被發送前剩下的秒數。如果沒有任何待處理的鬧鐘,就返回0。
接收信號
當進程p從內核模式返回到用戶模式(完成系統調用或上下文切換),內核會檢查p的未被阻塞待處理信號(pending & ~blocked)。若該集合為空,控制將轉移到p的邏輯控制流的下條指令$I{next}$ 。否則,內核選擇集合中某個信號k(通常為最小的k),然後強制進程接收。進程接收信號並完成指定行為,將控制傳遞給$I{next}$ 。
每個信號都有定義接收者接收到信號的默認行為:
- 進程終止。
- 進程終止並轉儲內存。
- 進程停止(掛起)直到被
SIGCONT重啟。 - 進程忽略該信號。
我們可以使用signal函數修改這種默認行為,需要注意SIGSTOP和SIGKILL的默認行為無法更改。
1 |
|
對於原始較難讀懂的函數聲明,可以使用typedef進行簡化。
以下我們解釋原始形式代碼應如何解讀:
1 | // 原始声明: |
通過設置handler更改行為:
SIG_IGN:忽略該信號。SIG_DFL:恢復默認行為。- 用戶定義函數:該函數稱為信號處理程序(signal handler),通過把處理程序的地址傳給
signal函數而改變行為的過程叫設置信號處理程序(installing the handler)。調用信號處理程序稱為捕獲信號(catching the signal),執行信號處理程序稱為處理信號(handling the signal)。
練習題
8.7
注意,只要休眠收到一個未被忽略的信號,sleep就會提前返回。所以對我們的handler來說,甚麼都不用做,只要立即返回即可。
1 |
|
阻塞和解除阻塞信號
隱式阻塞機制(Implicit blocking mechanism):內核默認阻塞與處理程序當前處理的信號相同類型者。例如程序捕獲信號$s$,正在運行處理程序 $S$,此時若發送第二次信號$s$,則$s$會一直保持待處理直到$S$返回。
顯式阻塞機制(Explicit blocking mechanism):使用sigprocmask與其輔助函數阻塞或解除阻塞指定信號。
1 |
|
sigprocmask通過how的值決定如何改變blocked位向量(阻塞信號集合):
SIG_BLOCK:blocked = blocked | setSIG_UNBLOCK:blocked = blocked & ~setSIG_SETMASK:blocked = set
編寫信號處理程序
信號處理程序因為以下因素導致難以編寫:
- 處理程序與主程序並發運行,共享相同全局變量,導致可能與主程序或其他處理程序互相干擾。
- 接收信號的規則有違直覺。
- 不同系統有不同信號處理語意。
安全的信號處理
處理程序應盡可能簡單:處理程序儘量只是設置全局標誌並立即返回,由主程序通過週期性的檢查和崇智標誌,以接收信號和處理。
處理程序僅調用異步信號安全的函數:異步信號安全(async-signal-safe) 函數可以安全的被處理程序調用,因為其可重入(reentrant) (被中斷後返回依舊可以正常運行,例如只訪問局部變量),或不能被信號處理程序中斷。
以下列出一些異步信號安全的函數:
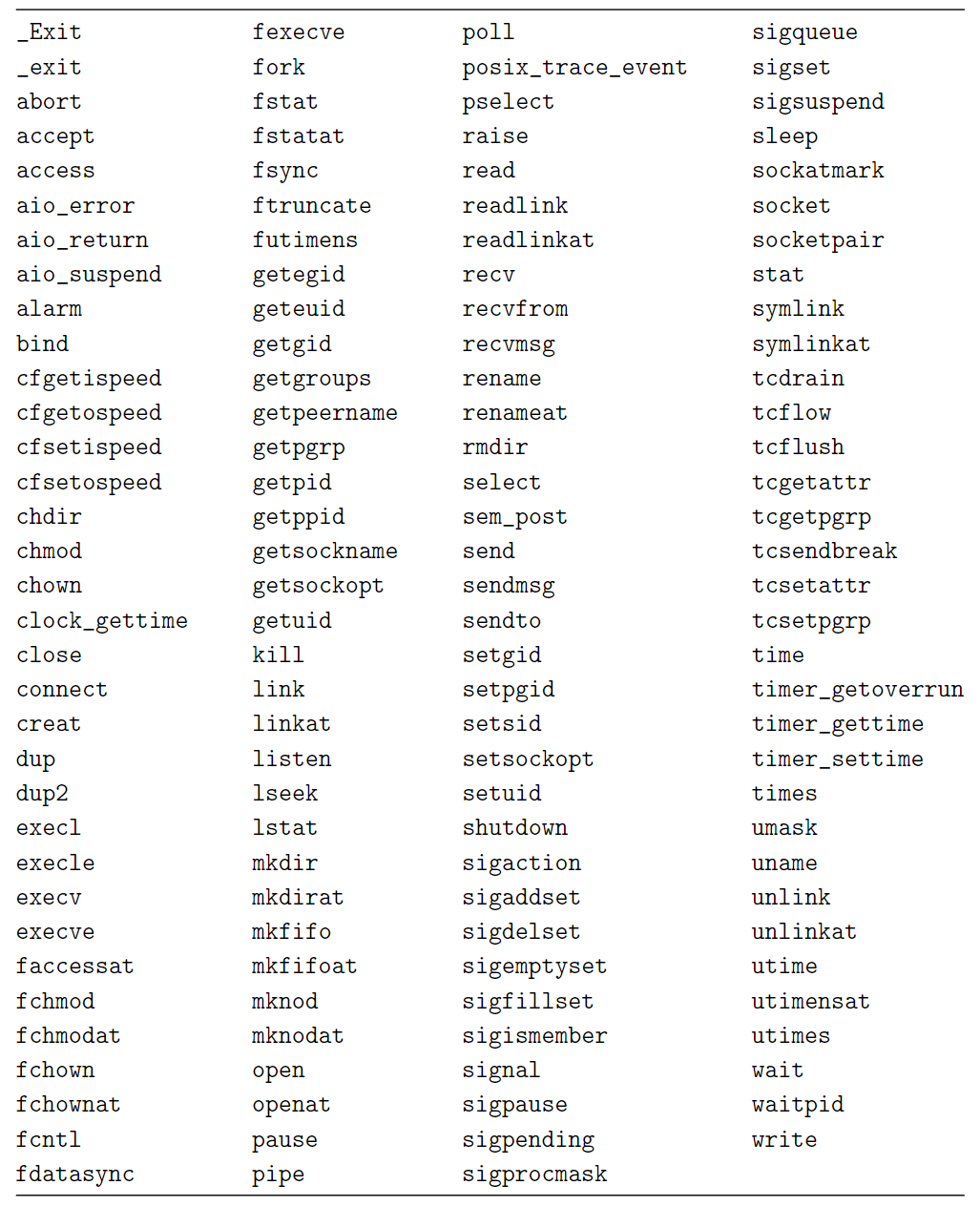
保存和恢復errno:在處理程序中調用異步信號安全函數仍可能干擾其他依賴於errno的代碼。在進入處理程序時應先將errno保存在局部變量中,返回時再恢復。
阻塞所有信號:若處理程序和主程序或其他處理程序共享全局數據結構,則在訪問該數據結構時需要阻塞所有信號,避免一系列訪問數據結構的指令被其他代碼中斷。
用volatile聲明全局變量:volatile可以告訴編譯器不要緩存該變量,將變量的值視為時刻在改變,每次訪問變量皆從內存中讀取。避免變量被並行代碼修改,卻仍從緩存中讀取未被修改的數值。
用sig_atmoic_t聲明標誌:EH通常會寫全局標誌紀錄信號的接收,主程序會週期性讀標誌並響應信號,再清除該標誌。對這種標誌,整形數據類型sig_atomic_t保證讀寫是原子性的(atomic) (不可中斷)。由於原子性,我們可以安全的讀寫標誌而不需暫時阻塞信號。注意,這裡的原子性僅包含單個讀寫。如flag++或flag = flag + 10是不適用的,因其需要多於一條指令實現。
正確的信號處理
注意,信號不會排隊。若連續發送兩次信號$k$,則待處理信號集合中只會有一個信號$k$,因為pending每種信號只有一位。
所以在父進程回收子進程的處理程序編寫上,需要小心這點。
1 | void handler(int signum) |
可移植的信號處理
signal語意各有不同:有些老Unix系統在每次對信號$k$捕獲後,會將信號$k$綁定的信號處理程序恢復到默認,需要手動再次設置。- 系統調用可被中斷:如
read, write, accept這樣的系統調用會潛在地阻塞進程一段間,稱慢速系統調用(slow system calls)。在老Unix系統中,捕獲信號導致慢速系統調用中斷,在處理程序返回後,不會繼續執行系統調用。需要程序員手動重啟被中斷的系統調用。
我們可以使用int sigaction(int signum, struct sigaction *act, struct sigaction *oldact)函數設置指定的信號處理語意。
我們可以編寫一個Signal包裝函數:
1 | handler_t *Signal(int signum, handler_t *handler) |
練習題
8.8
213
同步流以避免並發錯誤
有一種稱競爭(race) 的同步錯誤,當調用兩個有前後相關的函數時,若因系統調度而造成調用前後順序錯誤,就會造成隱密的bug。
比如我們想要在fork後,進行操作$p$,然後再回收子進程。此時,如果沒有專門處理,子進程可能在$p$還沒執行時就結束並發送信號SIGCHLD,導致先回收子進程才進行操作$p$。
我們可以如下處理:
1 | sigset_t mask, mask_all, prev; |
顯式地等待信號
我們使用函數int sigsuspend(const sigset_t *mask)等待信號。它會暫時使用mask替換當前的阻塞集合,然後掛起進程,直到收到信號。如果收到的信號的默認行為是終止,則進程不從sigsuspend返回就直接中指。
sigsuspend等價於以下代碼的原子版本:
1 | sigprocmask(SIG_SETMASK, &mask, &prev); |
非本地跳轉
C語言提供一種用戶級異常控制流形式,稱非本地跳轉(nonlocal jump),將控制直接從一個函數轉移到另一個運行中的函數,而不須正常調用。
1 |
|
setjmp經過一次調用,會有兩次返回:
- 第一次調用,設置
env緩衝區並返回0。 longjmp的env參數與setjmp設置的env緩衝區相同,setjmp會返回longjmp的參數retval的值。
非本地跳轉可以用來從深層嵌套的函數中立即返回。
1 |
|
非本地跳轉還可以使信號處理程序返回到指定的位置,而不是中斷處。可以用來實現軟重啟。
sigsetjmp, siglongjmp是可以被信號處理程序使用的版本。
1 |
|
需要注意,信號處理程序需要在sigsetjmp後調用,否則要承受處理程序在sigsetjmp前被調用的風險。
還有,因為sigsetjmp, siglongjmp不是異步信號安全函數,所以我們在siglongjmp可達處只調用異步信號安全函數。
操作進程的工具
strace:打印運行程序與其子進程的每個系統調用軌跡。ps:列出系統中的進程(包括殭屍進程)。top:列出當前進程資源使用的信息。pmap:顯示進程的內存映射。






![[GAMES 101] Rasterization 筆記](/pictures/SAO.jpg)


