
CSAPP U6 筆記與(部分)練習題解答
存儲技術
隨機訪問存儲器
靜態RAM
SRAM(Static Random-Access Memory)將每個位存放在雙穩態(bistable) 的存儲器單元裡。
SRAM可以(有電的情況下)無限期地保持在兩個不同的電壓配置(configuration,又稱狀態,state)之一。其他狀態都是不穩定的。SRAM會從不穩定狀態開始,迅速轉移到兩個穩定狀態中的一個。
SRAM較DRAM穩定。
動態RAM
DRAM(Dynamic Random-Access Memory)將每個位存儲為對一個電容的充電。
由於DRAM較敏感,且很多原因會導致漏電,使得DRAM單元會在10~100ms內失去電荷。內存系統需要週期性的讀出數據,並重寫刷新內存中的每一位。
| 每位晶體管數 | 相對訪問時間 | 持續的 | 敏感的 | 相對花費 | 應用 | |
|---|---|---|---|---|---|---|
| SRAM | 6 | $1\times$ | 是 | 否 | $1000\times$ | 高速緩存存儲區 |
| DRAM | 6 | $10\times$ | 否 | 是 | $1\times$ | 主存、幀緩衝區 |
傳統的DRAM
DRAM芯片中的單元(位)被分成$d$個超單元(supercell),每個超單元由$w$個DRAM單元組成。一個$d \times w$的DRAM總共存儲了$dw$位信息,其中$w$代表每個超單元可以存儲多少位。
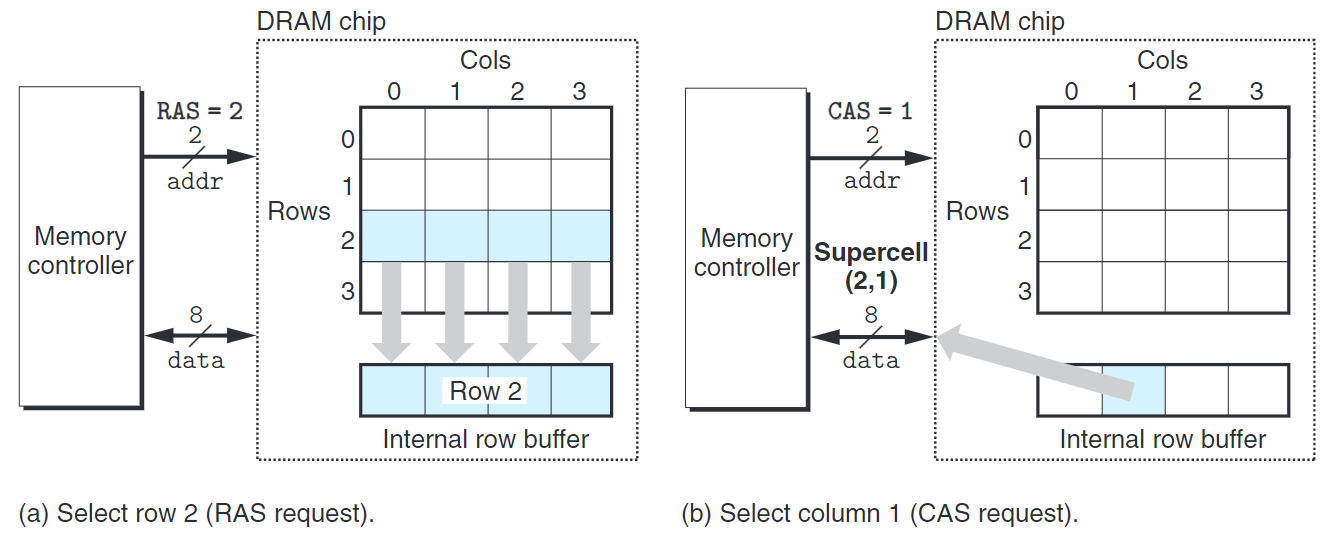
每個超單元有形如$(i,j)$的地址,$i$表示row,$j$表示column。
信息通過引腳(pin) 的外部連接器流入和流出芯片,每個引腳攜帶1位信號。
每個DRAM芯片連接到內存控制器(memory controller) 電路,此電路一次可以傳送或讀取$w$位數據。
讀出超單元$(i,j)$的內容時,內存控制器先將$i$傳給DRAM,然後才將$j$傳給DRAM,最後DRAM傳回$(i,j)$的內容。其中,$i$稱為RAS(Row Access Strobe)請求,$j$稱為CAS(Column Access Strobe)請求。注意,$i$和$j$共享一個DRAM地址引腳。
將DRAM組織成二維陣列而不是線性數組的原因是:假設128位($16 \times 8$)DRAM被組織成一個16個超單元的線性數組,地址為0~15,芯片需要4個地址引腳而不是2個。
二維陣列的缺點是訪問時間較長(分兩步驟)。
內存模塊
DRAM芯片封裝在內存模塊(memory module) 中,它插到主板的擴展槽上。
下圖展示一個內存模塊的基本模型。
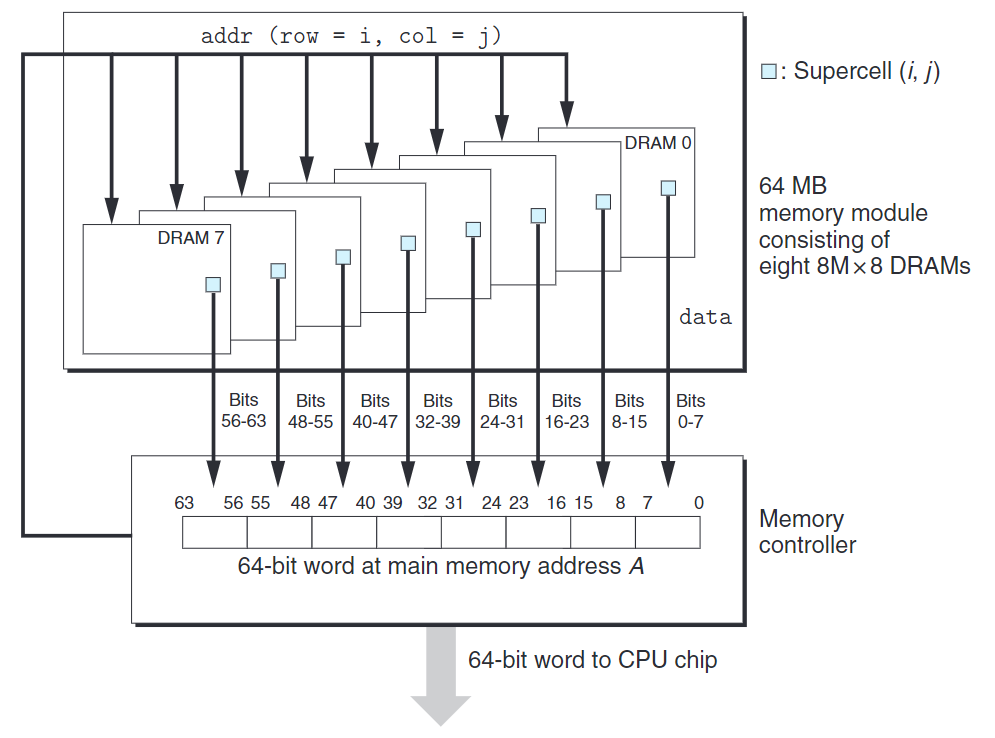
圖中展示8個DRAM,每個DRAM存儲64MB($8M \times 8$),且這8個芯片編號0~7。
要存儲8字節(64位)的數據,每個DRAM中的一個超單元會存儲主存的一個字節。其中,DRAM 0存儲第一個(低位)字節,依此類推。
要取出內存地址A的一個字,內存控制器將A轉換成一個超單元地址$(i,j)$並發送到內存模塊,然後內存模塊將$i$和$j$廣播到每個DRAM。最後,將每個DRAM的響應合成為一個64位字,再返回給內存控制器。
將多個內存模塊連接到內存控制器,可以合成主存。此時,當控制器收到地址A時,控制器選擇包含A的模塊$k$,將A轉換成$(i,j)$形式,並發送到模塊$k$。
練習題
6.1
| 組織 | $r$ | $c$ | $b_{r}$ | $b_{c}$ | $max(b{r}, b{c})$ |
|---|---|---|---|---|---|
| $16\times 1$ | 4 | 4 | 2 | 2 | 2 |
| $16 \times 4$ | 4 | 4 | 2 | 2 | 2 |
| $128 \times 8$ | 16 | 8 | 4 | 3 | 4 |
| $512 \times 4$ | 32 | 16 | 5 | 4 | 5 |
| $1024 \times 4$ | 32 | 32 | 5 | 5 | 5 |
非易失性存儲器
若斷電,DRAM和SRAM會丟失信息。此時,它們是易失的(volatile)。另一方面,非易失性存除器(nonvolatile memory) 在斷電後仍保存信息。
只讀存儲器(Read-Only Memory, ROM) 由於歷史原因,有些類型可讀也可寫。ROM以能被重編程(寫)的次數和重編程的機制來區分。
PROM(Programmable ROM,可編程ROM)只能被編程一次,PROM的存儲器單元有一種熔絲(fuse),只能被高壓電熔斷一次。
可擦寫可編程 ROM(Erasable Programmable ROM, EPROM) 允許使用紫外線將單元清除成0。對EPROM編程需要使用特殊設備。
電子可擦除 PROM(Electrically Erasable PROM, EEPROM) 類似EPROM,但不需要獨立的編程設備。
閃存(flash memory) 基於ERPROM。
存儲在ROM中的程序被稱為固件(firmware)。當計算機系統通電後,就會運行固件。
訪問主存
數據流通過總線(bus) 在CPU和主存傳遞。每次數據傳輸通過一系列步驟完成,稱這些步驟總線事務(bus transaction)。讀事務(read transaction) 從主存傳遞數據到CPU,寫事務(write transaction) 從CPU傳遞數據到主存。
總線是一組並行的導線,可以攜帶地址、數據和控制信號。控制線攜帶的信號會同步事務,並標示出當前正在執行的總線類型。
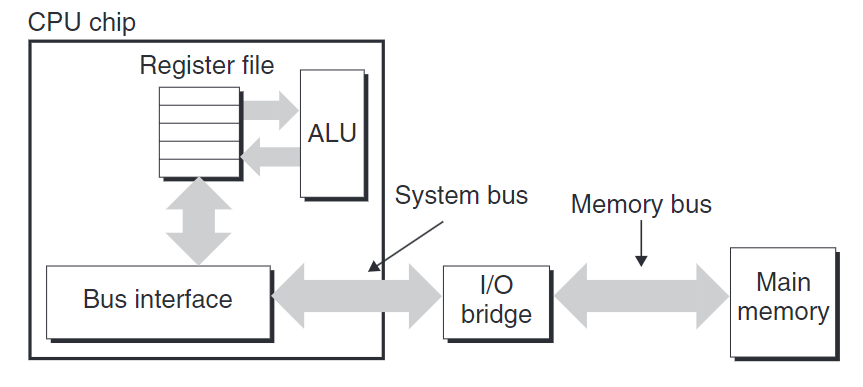
上圖展示一個計算機系統的配置。
主要部件是CPU、I/O橋接器(I/O bridge,包括內存控制器)和主存。
這些部件由一對總線連接,系統總線(system bus)和內存總線(memory bus)。I/O橋接器會將系統總線的信號轉換成內存總線的信號。
考慮以下操作:
1 | movq A, %rax |
地址A要被加載到%rax中。CPU中稱為總線接口(bus interface) 的電路在總線上發起讀事務。
讀事務由三步驟組成:
- CPU將地址A放到系統總線上,I/O橋將信號傳遞到內存總線。
- 主存收到內存總線的信號,從內存總線讀取地址,再從DRAM取出數據,並將數據寫到內存總線。I/O橋傳遞到系統總線。
- CPU收到信號,更新
%rax。
反過來,考慮以下操作:
1 | movq %rax, A |
寫事務由三個步驟組成:
- CPU將地址傳遞,內存從內存總線讀出地址,並等待數據到達。
- CPU將
%rax中的數據傳遞。 - 主存從內存總線讀數據,並將數據存儲到DRAM中。
磁盤存儲
磁盤由盤片(platter) 構成,每個盤面有兩面,稱為表面(surface)。盤片中央有一個可以旋轉的主軸(spindle),使得盤片以固定旋轉速率(rotational rate) 旋轉,通常是5400~15000轉每分鐘(Revolution Per Minute, RPM)。
每個表面由多組稱磁道(track) 的同心圓組成。每個磁道被劃分成多組扇區(sector),每個扇區通常包含512字節的數據。扇區間由間隙隔開,間隙存儲用來標示扇區的格式化位。
硬盤的容量由以下因素決定:
- 紀錄密度(recodring density):磁道一英吋的段中可以放入的位數。
- 磁道密度(track density):從盤片中心出發半徑上一英吋內可以有的磁道數。
- 面密度(areal density):紀錄密度和磁道密度的乘積。
磁盤用讀/寫頭(read/write head) 來讀寫存儲在磁性表面的位,讀寫頭連接到傳動臂(actuator arm) 的一端。每個盤面都有一個獨立的讀寫頭。
通過延半徑前後移動,傳動臂可以將讀寫頭定位道任何磁道上,此行為稱尋道(seek)。
對扇區的訪問時間(access time) 由三個因素決定:尋道時間(seek time)、旋轉時間(rotational latency)、傳送時間(transfer time)。
- 尋道時間($T_{se ek }$):移動傳動臂所需的時間。
- 旋轉時間($T_{\text{rotation}}$):驅動器等待目標扇區的第一位旋轉到讀寫頭下的時間。
- 傳送時間($T_{\text{transfer}}$):轉過一個扇區所需的時間。
為了對操作系統隱藏不必要的複雜,現代磁盤將結構呈現為更簡單的視圖:一個$B$個扇區大小的邏輯塊序列,編號為$0,1,\cdots ,B-1$。
磁盤封裝中有一個設備,稱作磁盤控制器,維護著邏輯塊號與物理磁盤扇區間的映射關係。
當系統要執行一個I/O操作時,會發送命令到磁盤控制器,讓其讀取某個邏輯塊號。控制器上的固件會執行快速表查找,將邏輯塊號轉換成$(盤面,磁道,扇區)$的三元組。控制器的硬件會解釋該三元組,控制讀寫頭移動到該區並執行操作。
如顯卡、鼠標、鍵盤等I/O設備,都是通過I/O總線連接到CPU和主存的。與系統總線和內存總線不同,I/O總線設計與底層CPU無關。
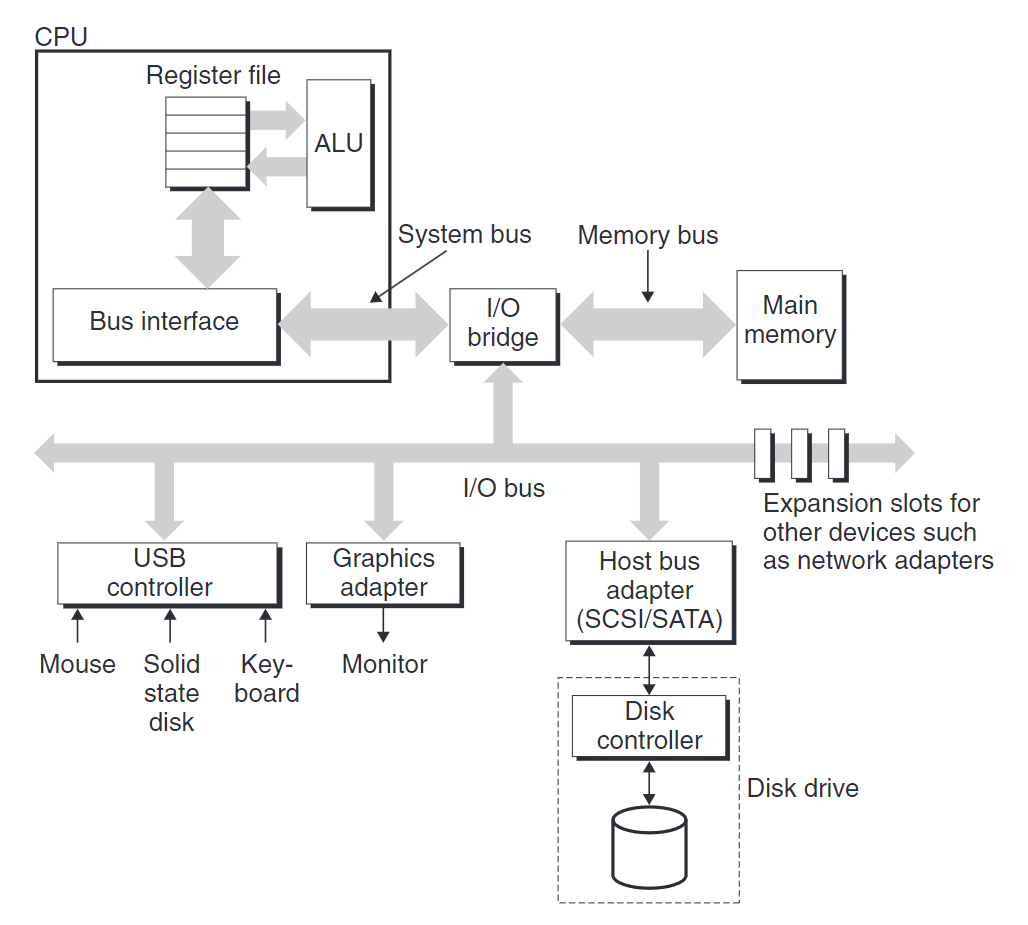
上圖為一個I/O總線結構,它連接了CPU、主存和I/O設備。
I/O總線較系統、內存總線慢,但可容納第三方I/O設備:
- 通用串行總線(Universal Serial Bus, USB)
- 圖形卡或適配器
- 主機總線適配器(Host Bus Adapter):將磁盤連接到I/O總線,使用的是主機總線接口定義的通信協議。SCSI(讀scuzzy)和SATA(讀sat-uh)是兩個最常用的磁盤接口,SCSI比SATA快且支持多個磁盤驅動器。
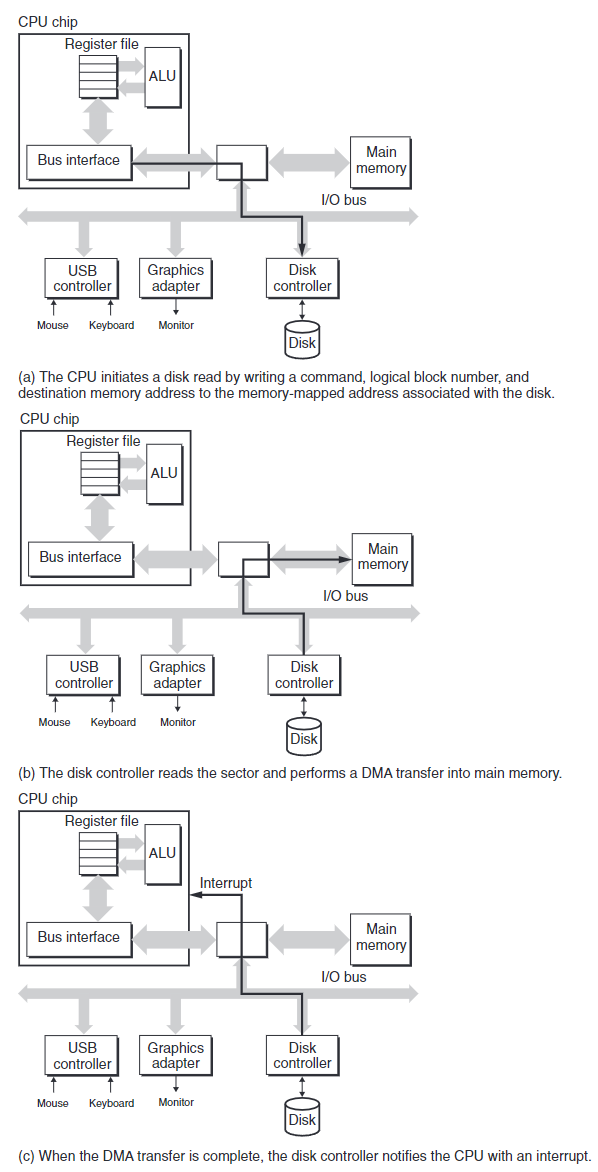
CPU使用內存映射I/O(memory-mapped I/O) 向設備發送指令。在系統中,地址空間中有一塊地址為I/O通信保留,每個這樣的地址稱I/O端口(I/O port)。當一個設備連接到總線時,它被映射到一個或多個端口。
假設磁盤控制器映射到端口0xa0。則CPU通過三個對地址0xa0的存儲指令發起磁盤讀:
- 發送命令字,告訴磁盤發起了磁盤讀,並包含其他參數,比如讀完成後是否中斷CPU。
- 指明讀的邏輯塊號。
- 指明哪個主存地址應儲存磁盤扇區中的內容。
當磁盤控制器接收到CPU的指令,它會將邏輯塊號翻譯成扇區地址,並讀取該扇區中的內容,然後直接將該內容傳入主存,不需要CPU的干涉。
設備可執行寫或讀總線事務而不經過CPU干涉的過程,稱直接內存訪問(Direct Memory Access, DMA)。而這種數據傳送稱DMA傳送(DMA transfer)。
DMA傳送完成後,磁盤控制器給CPU發送中斷信號。當CPU芯片引腳收到信號,會導致CPU暫停當前操作,跳轉到操作系統例程,該程序會記錄I/O完成,然後將控制返回到CPU被中斷的地方。
以上行為如下圖所示:
練習題
6.3
$T_{\text{avg rotation}} = \frac{1}{2}\times \frac{1}{15000}min \times 60s \times 1000ms \approx 2ms$
$T_{\text{avg transfer}} = \frac{1}{15000}\text{min}\times \frac{1}{500} \times 60s \times 1000ms \approx 0.008ms$
$T_{access} = 8+2+0.008 \approx 10ms$
固態硬盤
固態硬盤(Solid State Disk, SSD) 基於閃存。一個SSD封裝由一個或多個閃存和閃存翻譯層(flash translation layer) 組成,閃存翻譯層是一個硬件/固件設備,充當磁盤控制器的角色,將對邏輯塊的請求翻譯成對底層物理設備的訪問。
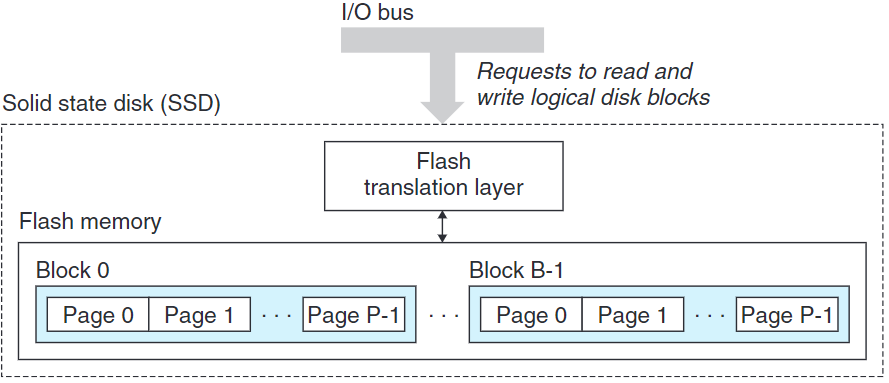
一個閃存由$B$個塊組成,每個塊由$P$個頁組成。通常,頁的大小為512字節到4KB,塊由32到128頁組成,塊的大小為16KB到512KB。
數據以頁為單位進行讀寫,但只有在頁所屬的塊被擦除後,才能寫這一頁(通常指該塊所有位被設為1)。
隨機寫很慢,有兩個原因:
- 擦除塊需要很長的時間,1ms級,比訪問頁慢了一個數量級。
- 若操作試圖修改包含已經有數據的頁$p$(即非全1),則該塊中所有帶有有效數據的頁都必須複製到一個(擦除過的)新塊,然後才能進行對頁$p$的寫。
局部性
局部性(locality) 通常有兩種不同形式:
- 時間局部性(temporal locality):被引用過的內存位置很可能在不久被多次引用。
- 空間局部性(spatial locality):一個內存位置被引用過後,附近的內存位置很可能在不久被引用。
高速緩存存儲器保存最近被引用的指令和數據,從而提高對主存的訪問速度。
在操作系統級,局部性原理使得系統使用主存作為虛擬地址最近被引用塊的高速緩存。類似地,操作系統用主存來緩存磁盤文件中最近被使用的磁盤塊。
考慮以下代碼:
1 | int sumvec(int v[N]) { |
其中,sum具有良好的時間局部性,且因為sum是標量,所以沒有空間局部性。而對v來說,它具有良好的空間局部性,但是時間局部性卻很差,因為函數中從不會多次調用v的同一項。
像sumvec這樣順序訪問一個向量每個元素的函數,稱步長為1的引用模式(stride-1 reference pattern,或稱順序引用模式 sequential reference pattern)(相對於元素的大小)。在一個向量中,每隔$k$個元素進行訪問,就稱步長為$k$的引用模式(stride-k reference pattern)。一般來說,$k$越大,空間局部性越小。
對於取指令來說,循環有好的時間、空間局部性。循環體越小,循環迭代次數越多,局部性越好。
練習題
6.7
1 | int sumarray3d(int a[N][N][N]) { |
6.8
clear1 > clear2 > clear3
分兩部分看:首先clear1和clear2有同樣的raw-major ordered讀數組,比clear3的column-major oredered空間局部性好。其次,因為結構體內的變量在內存中線性排列,所以clear1統一設置完一個結構再設置下一個結構的行為比clear2的空間局部性好。
存儲器層次結構
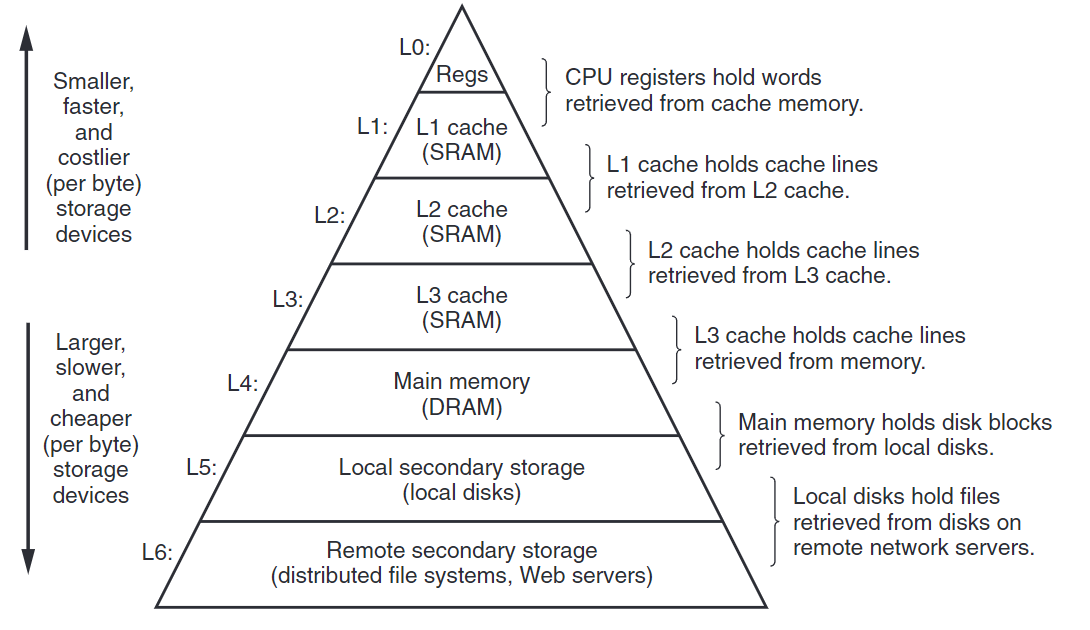
下圖是一個典型的存儲器層次結構(memory hierarchy)。
存儲器層次結構中的緩存
存儲器層次結構的中心思想是,對於每層$k$,會做為$k+1$層的緩存。
第$k+1$層的存儲器被劃分成連續的數據對象組塊(chunk),稱為塊(block)。而第$k$層則被劃分成更少塊的集合,且每個塊的大小與第$k+1$一樣。第$k$層的緩存是$k+1$層塊的子集副本。
數據以塊大小為傳送單元(transfer unit) 在兩層之間來回複製。
雖然相鄰的層次之間塊大小是固定的,但是其他的層次對之間可以有不同大小的塊。
當程序需要$k+1$層的數據$d$時,程序首先在第$k$層尋找$d$,如果$d$緩存在$k$,則緩存命中(cache hit),否則緩存不命中(cache miss)。
緩存不命中時,需要覆蓋一個現存的塊,稱替換(replacing) 或 驅逐(evicting) 這個塊。被驅逐的塊稱犧牲塊(victim block)。
強制性不命中(compulsory miss,或稱冷不命中, cold miss):第$k$層為空(冷緩存, cold cache)時發生。不會在反覆訪問存儲器使得緩存暖身(warmed up) 後發生。
當不命中時,需要執行放置策略(placement policy) 以確定將$k+1$層的塊放置在哪。例如第$k+1$層的塊必須放在第$k$層的塊$(i \text{ mod } 4)$中。此時,容易引發衝突不命中(conflict miss),如果程序反覆請求塊0和塊8,則每次引用都不會命中,即使這個緩存可以容納大於兩個塊。
高速緩存存儲器
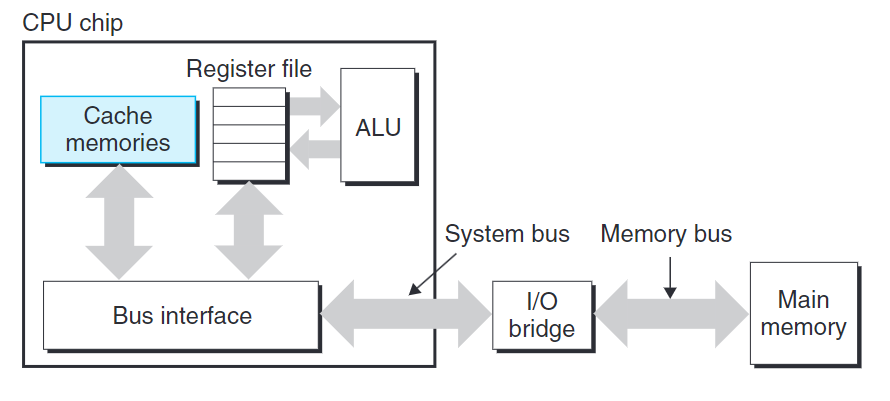
由於CPU和主存的差距漸大,設計者在CPU寄存器文件與主存之間插入一個SRAM高速緩存存儲器,稱為L1高速緩存或一級緩存,典型的訪問時間是4個時鐘週期。
通用的高速緩存存儲器組織結構
考慮一個系統,其存儲器地址有$m$位,形成$M=2^{m}$個不同的地址。
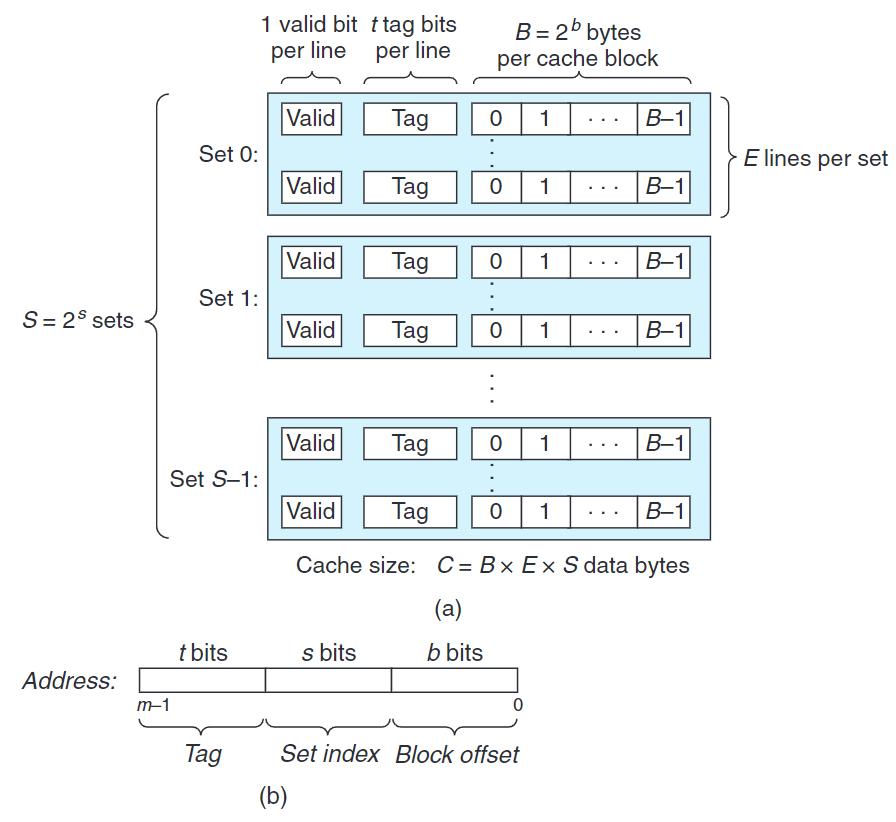
如圖所示,高速緩存被組織成有$S=2^{s}$個高速緩存組的數組。每個組包含$E$個高速緩存行(cache line)。每個行由一個有效位(valid bit),一個$B=2^{b}$字節的數據塊(block),還有$t=m-(b+s)$個標記位(tag bit) 組成。
高速緩存結構可以用$(S, E, B, m)$描述。而高速緩存的大小指所有數據塊地和,即$C=S\times E\times B$。
如何檢查緩存中是否包含某個元素:
- 將$m$劃分成三個字段,其中$s$個組引索位指明是$S$中的哪一項。
- $t$個標記位指明該組的哪一行包含這個數據,同時確認數據是否有效。
- 最後,由$b$個塊偏移位指明在$B$個字節的數據塊中的偏移。
練習題
6.9
| 高速緩存 | $m$ | $C$ | $B$ | $E$ | $S$ | $t$ | $s$ | $b$ |
|---|---|---|---|---|---|---|---|---|
| 1. | 32 | 1024 | 4 | 1 | 256 | 22 | 8 | 2 |
| 2. | 32 | 1024 | 8 | 4 | 32 | 24 | 5 | 3 |
| 3. | 32 | 1024 | 32 | 32 | 1 | 27 | 0 | 5 |
直接映射高速緩存
依據每個組的高速緩存行數$E$,高速緩存被分成不同類。在$E=1$的情況下,我們稱直接映射高速緩存(direct-mapped cache)。以下,我們使用直接映射高速緩存介紹通用概念。
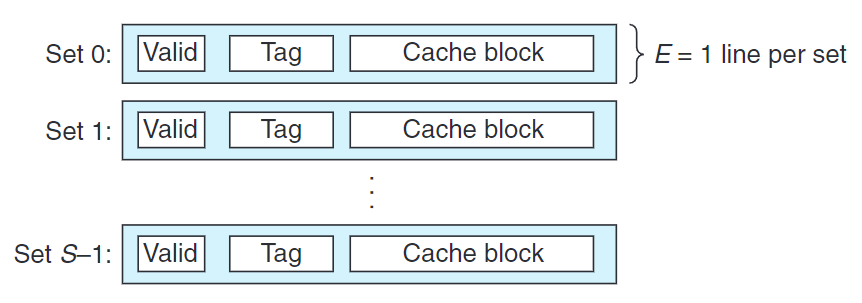
高速緩存確定一個請求是否命中,然後抽出被請求字的過程,分三步:
- 組選擇
- 行匹配
- 字抽取
1.組選擇
高速緩存從$w$的地址中間取出$s$個組索引位,並將其解釋成對應組號(無符號數)。
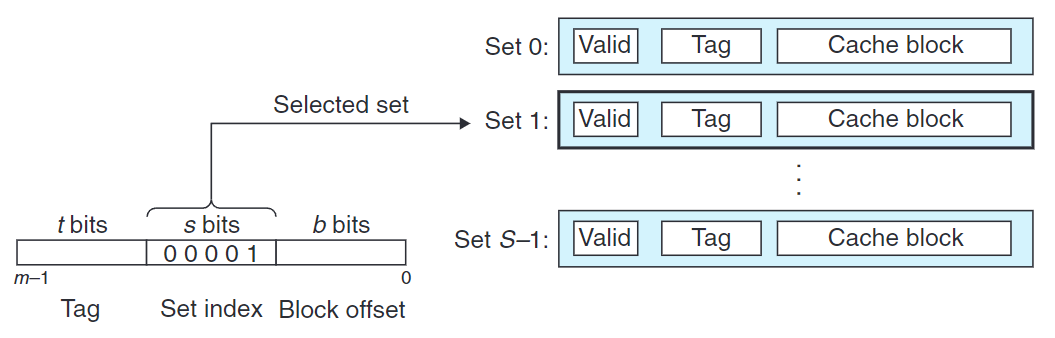
2.行匹配
當確認該行設置了有效位後,確認高速緩存行中的標記是否與$w$的地址中的標記相匹配。
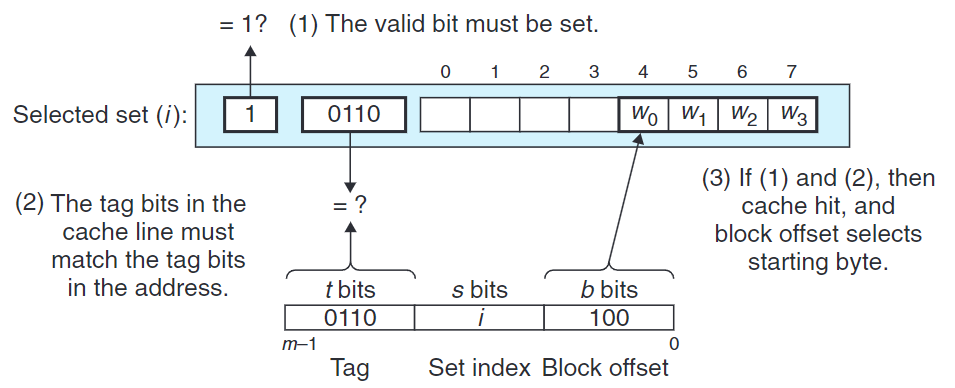
3.字抽取
確認命中後,我們需要從塊中取得我們需要的字。通過塊偏移位我們可以將高速緩存看做數組,通過偏移來訪問。
4.緩存不命中時的行替換
若緩存不命中,需要從存儲器結構中的下一層取出被請求的塊。
對於直接映射高速緩存來說,替換策略是:用新的行替換當前行。
5.直接映射衝突不命中
回想衝突不命中的概念,即:有足夠的高速緩存空間,但是塊卻交替地映射到同一個組。
當程序訪問大小為2的冪的數組時,直接映射高速緩存通常會發生衝突不命中。
考慮以下函數:
1 | float dotprod(float x[8], float y[8]) { |
按理來說,x和y具有良好的空間局部性,所以命中率較高。可事實完全相反,命中率很低。
假設一個塊16字節,且高速緩存中有兩個組,每個組只能容納一行。我們可以得到下表:
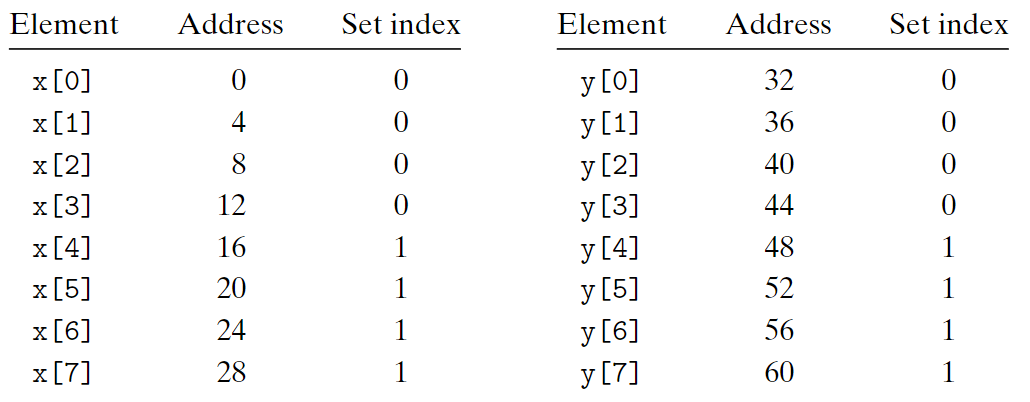
由上表可見,每次對x和y的引用都會導致衝突不命中,因為我們在x和y的塊之間抖動(thrash)。抖動指的是高速緩存反覆地加載和驅逐相同組中的塊。
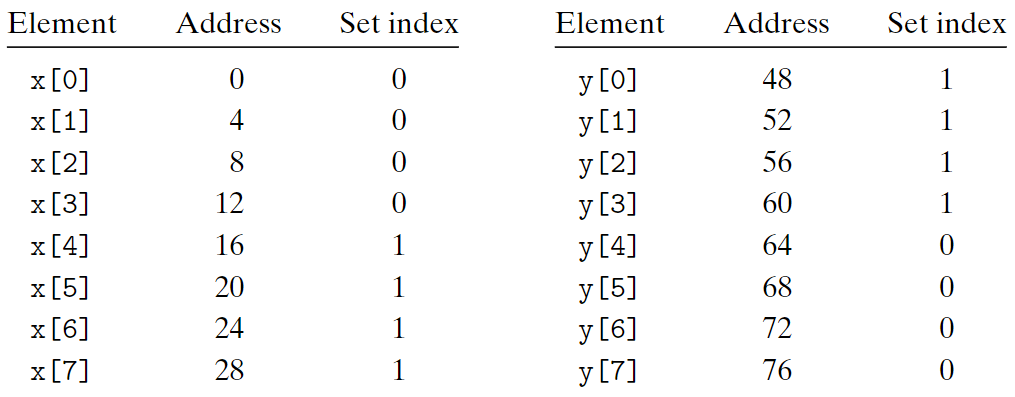
想修正抖動,我們可以在數組結尾處填充$B$個字節。例如將x[8]改為x[12],即填充16字節(4個浮點數)。
練習題
6.10
命中率:3/4
6.11
A. 有$2^{t}$個塊
B.
$s=9, t=18, b=5$
$\frac{4096\times4}{32} < 2^{18}$所以array中的所有數據都被映射在同一組中,即最大數量為1。
組相聯高速緩存
直接映射高速緩存發生衝突不命中的原因在於每個組只有一行的限制,而組相聯高速緩存(set associative cache) 則放鬆了這條限制。
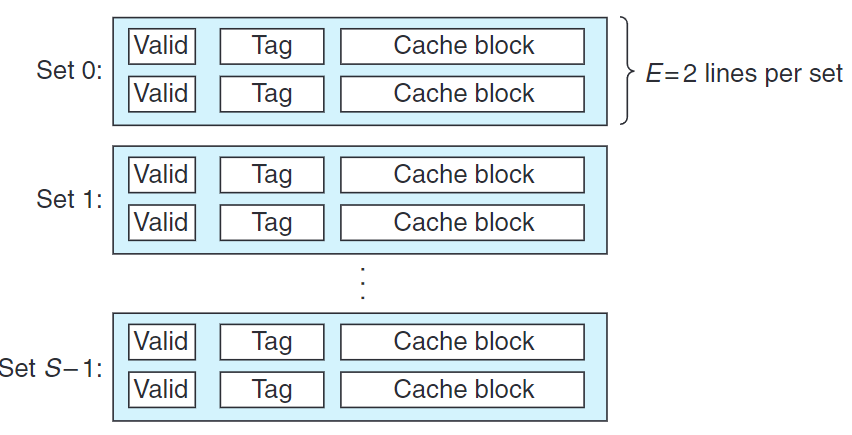
對一個$1 < E < \frac{C}{B}$的高速緩存稱$E$路組相聯高速緩存。
下圖展示了一個2路組相聯高速緩存的結構。
1.組選擇:與直接映射高速緩存的組選擇方法相同。
2.行匹配與字選擇
傳統內存像數組,而相聯存儲器更像一個哈希表,利用(key, value)存放數據。
由於組相聯高速緩存一個組內有多行,所以必須搜索組中每行,確認有效,並匹配標記。
3.緩存不命中時的行替換
緩存不命中時,若組內有空行則直接加載入該行。
若沒有空行,可以使用以下幾個策略:
- 隨機選擇
- 最不常使用(Least-Frequently-Used, LFU):引用次數最少
- 最近最少使用(Least-Recently-Used, LRU):最後一次訪問最久遠
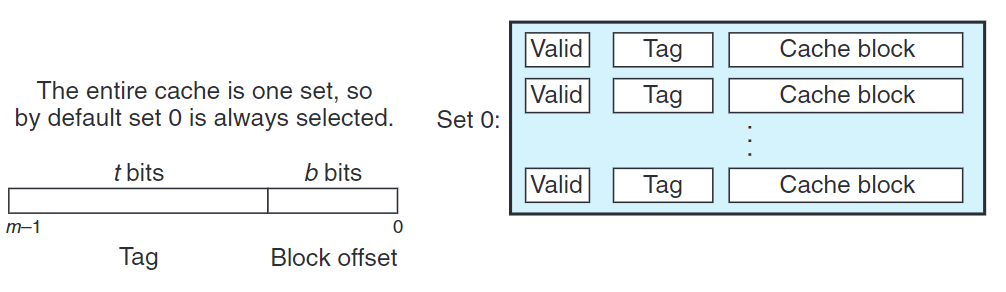
全相聯高速緩存
全相聯高速緩存(fully associative cache) 一個組包含所有高速換存行($E=\frac{C}{B}$)。
1.組選擇
注意,全相聯高速緩存下,地址沒有組索引位。
練習題
6.12
CO: 1~0
CI: 4~2
CT: 12~5
6.13
A. 0111000110100
B.
| 參數 | 值 |
|---|---|
| CO | 0x0 |
| CI | 0x5 |
| CT | 0x71 |
| 緩存命中? | 是 |
| 返回的字節 | 0xB |
6.14
A. 0110111010101
B.
| 參數 | 值 |
|---|---|
| CO | 0x1 |
| CI | 0x5 |
| CT | 0x6E |
| 緩存命中? | 否 |
| 返回的字節 | - |
6.15
A. 1111111100100
B.
| 參數 | 值 |
|---|---|
| CO | 0x0 |
| CI | 0x1 |
| CT | 0xFF |
| 緩存命中? | 否 |
| 返回的字節 | - |
6.16
0011001001100 0011001001101 0011001001110 0011001001111
0x64C 0x64D 0x64E 0x64F
有關寫的問題
讀取上文已經介紹過了,現在來考慮寫的問題,假設我們要寫一個已經緩存的字$w$(寫命中,write hit)。
寫命中時,兩種方法:
- 直寫(write-through):立即將$w$的高速緩存塊寫入到低一層中。
- 寫回(write-back):推遲更新,僅當替換算法要驅逐該塊時,才寫入到低一層中。缺點是必須額外維護一個修改位(dirty bit),表明該塊是否被修改過。
寫不命中時,兩種方法:
- 寫分配(write-allocate):加載低一層的塊到高速緩存中,然後更新。寫回高速緩存通常使用。
- 非寫分配(not-write-allocate):避開高速緩存,直接將字寫到低一層中。直寫高速緩存通常使用。
編寫高速緩存友好的代碼
以下是編寫高速緩存友好(cache friendly) 代碼的基本方法:
- 讓最常見的情況跑得快
- 減少循環內部的緩存不命中數
一個步長為$k$的引用模式($k$以字為單位)平均每次迭代會有$\text{min}\left( 1,\text{wordsize}\times k\times \frac{1}{B} \right)$次緩存不命中。
對於局部變量,合理優化的編譯器會將它們緩存在寄存器文件中,即最高層。
對多維數組來說,空間局部性非常重要。
練習題
6.17
$S=2,B=8,s=1,b=3$
A.
dst |
0 | 1 |
|---|---|---|
| 0 | m | m |
| 1 | m | m |
| src | 0 | 1 |
|---|---|---|
| 0 | m | |
| 1 | m | h |
src[0][1]是m,因為高速緩存空間有限, 對dst[0][0]的寫會驅逐src[0][0]加載時的那一行。
B.
| dst | 0 | 1 |
|---|---|---|
| 0 | m | h |
| 1 | m | h |
| src | 0 | 1 |
|---|---|---|
| 0 | m | h |
| 1 | m | h |
6.18
$S=64, B=16(\text{4個int,兩個algae_position}), s=6, b=4$
A. 512
B.
$8\times 16=128$
因為x與y分開使用兩個循環讀取,而一次循環有256次讀操作,大於高速緩存組的總數,所以讀y時並不會由於上方循環的緩存而命中。
$128 \times 2 =256$
C. 1/2
6.19
A. 512
B.
$16\times 8=128 \ \times$
因為組數量為64,只能存儲一半的數組,所以當訪問到grid[8][0]時,會將grid[0][0]的塊驅逐(如果通過地址計算,二者映射到的組相同)。導致下次訪問grid[0][1]時不命中(衝突不命中)。所以正確答案是:
$16 \times 16 = 256$
C. 1/2
D. 1/4
6.20
A. 512
B. $8 \times 16=128$
C. 1/4
D. 1/4
綜合:高速緩存對程序性能的影響
重新排列循環以提高空間局部性
考慮上式矩陣相乘操作,通常使用三個嵌套的循環實現。排列三個變量i, j, k可以取得三種不同的版本。
為了分析各版本,做以下假設:
- 每個數組都是
double類型,sizeof(double) == 8。 - 只有一個高速緩存,其塊大小為32字節。
- 數組大小
n很大,矩陣的任一行都沒法完全裝進L1高速緩存中。

(a)與(b)每次迭代執行兩個加載。內循環以步長1掃描數組A的一行,A的不命中率為每次迭代不命中0.25次。以步長1掃描數組B的一列,因為n夠大,所以每次對B的訪問都不會命中,B的每次迭代都不命中。所以每次迭代總和會有1.25次不命中。
(c)與(d)每次迭代執行兩個加載和一個存儲。內循環掃描A與C的列,每次都不命中,所以每次迭代有2次不命中。
(e)與(j)每次迭代執行兩個加載和一個儲存。內循環掃描B和C的行,每次迭代每個數組只有0.25次不命中,所以每次迭代有0.5次不命中。
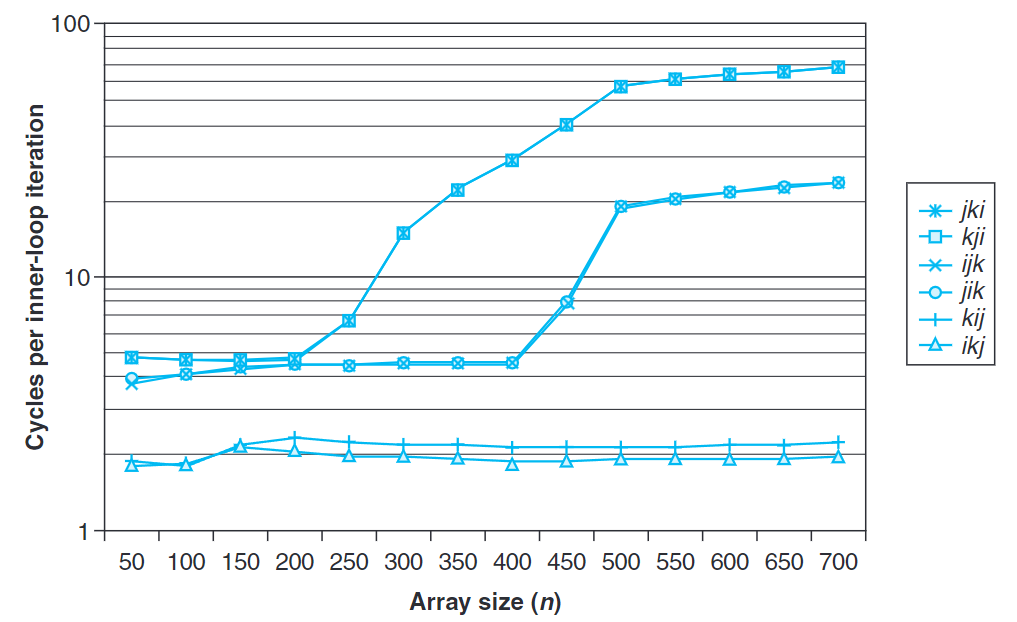
當n較大時,kij與ikj版本性能保持不變。這是因為預取(prefetching) 硬件識別出這是步長為1的訪問模式,事先在訪問之前將數據取到高速緩存中,使得就算數組大小大於SRAM可以存儲的大小也能保持良好性能。






![[GAMES 101] Rasterization 筆記](/pictures/SAO.jpg)


