
CSAPP U4 筆記與(部分)練習題解答
Y86-64指令集體系結構
Y86-64
這部分為書中作者定義的ISA,不做過多筆記,去翻書吧。
練習題
4.1
1 | 30 F3 0F 00 00 00 00 00 00 00 |
4.2
略好不好,都是查表浪費時間的題目。
4.3 ~ 4.6
略
4.7
表示執行pushq %rsp時執行的行為是壓入%rsp的原始值。
4.8
表示彈出%rsp的原始值。
邏輯設計和硬件控制語言HCL
邏輯門
邏輯門是數字電路的基本計算單元。AND用&&表示,OR用||表示,而NOT用!表示,不使用&、|和~表示則是因為邏輯門只對單個位的數進行操作,而不是整個字。
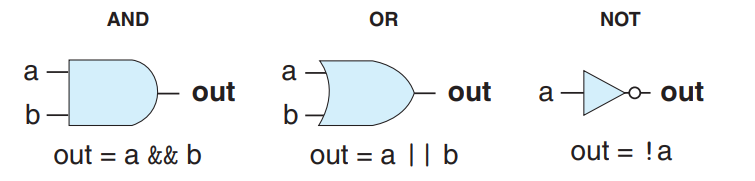
組合電路和HCL布爾表達式
組合電路:多個邏輯門組成一個網而構建成的計算塊 (computational block)
構建網的幾個限制:
- 邏輯門的輸入必須由下述輸出提供:
- 系統輸入 (主輸入)
- 存儲器單元輸出
- 邏輯門輸出
- 兩個或多個邏輯門的輸出不能連接在一起,否則它們可能會使線上的信號矛盾,導致不合法的電壓或電路故障。
- 網必須是無環的,否則會導致該網絡計算的函數有歧異。
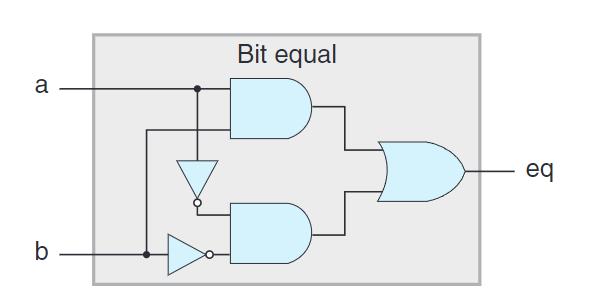
上圖為一個組合電路的例子。接收兩個輸入a與b,若a與b都為1或a與b都為0則eq輸出1。 用HCL寫這個網的函數就是:
1 | bool eq = (a && b) || (!a && !b); |
需要注意我們不把上述代碼看成執行計算後將結果放入內存中某個位置,相反他只是給表達式一個名字。
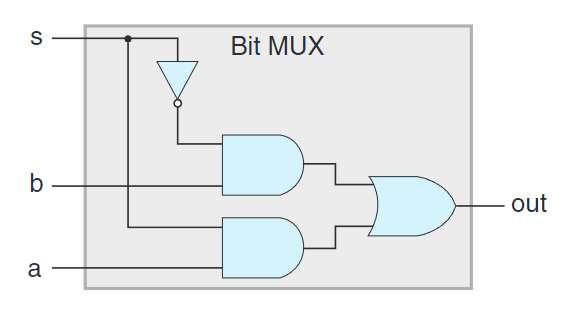
上圖為多路復用器 (multiplexor,MUX) 。在這個單個位的多路復用器中,數據信號為a與b,控制信號是輸入位s。當s為1則輸出a,若s為0則輸出b。HCL表達式為:
1 | bool out = (s && a) || (!s &&b); |
HCL與C表達式的區別:
- 組合電路的輸出會持續響應輸出的變化。即輸入改變後,經過一定延遲輸出也會相應改變。相比之下C只會在程序執行過程中遇到時才會求值。
- C的邏輯表達式允許任意整數,
0表示FALSE,其他值表示TRUE。而邏輯門只對0進行操作1。 - C的邏輯表達式可能只被部分求值,如果一個
AND或OR操作的結果只用第一個參數求值就可以確定,那麼就不會對第二個參數求值了。而組合邏輯沒有這種規則。
練習題
4.9
1 | bool xor = (a && !b) || (!a && b); |
通常xor與eq是互補的,一個為1另一個就為0。
字級的組合電路和HCL整數表達式
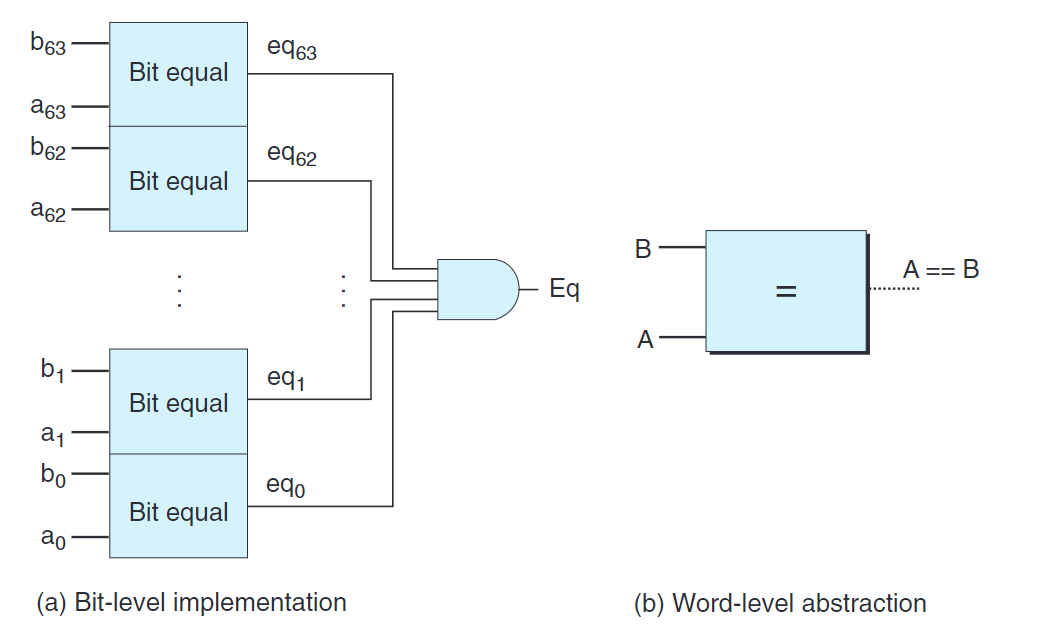
上圖 (a) 執行字級計算的組合電路根據輸入字的各個位用邏輯門計算,測試A與B是否相等。這個電路由64個上文提到的Bit equal電路實現。
在HCL中,我們將所有字級的信號都聲明為int,不指定字的大小。這樣做是為了方便,但在全功能的硬建描述語言中,每個字都可以聲明為特定的位數。HCL允許比較字是否相等:
1 | bool Eq = (A == B); // 此處A與B是int類型 |
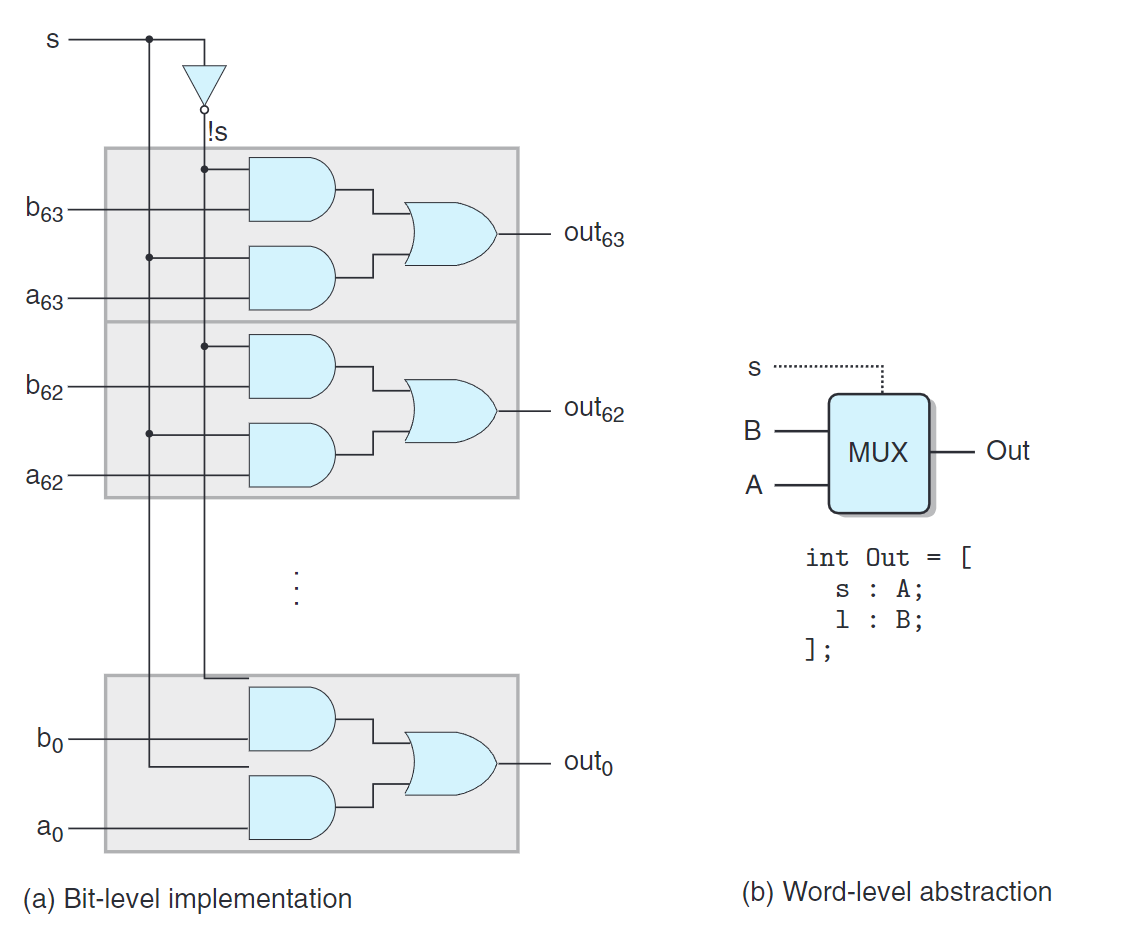
上圖是字級的多路復用器電路,與上文介紹的類似,但是不是簡單的複製黏貼。它只對s執行一次NOT操作,然後在每個位處複用它以減少反相器或非門 (inverters) 的數量。
在HCL中,MUX用情況表達式 (case expression) 描述。 情況表達式的通用格是如下:
1 | [ |
每種情況$i$都有一個布爾表達式$select{i}$和一個整數表達式$expr{i}$。前者表明甚麼時候選擇這種情況,後者指明得到的值。
與C的switch不同,我們不要求不同的選擇表達式之間互斥。這種選擇表達式是順序求值的,且第一個為1者會被選中。字級多路復用器的HCL描述就是:
1 | word Out = [ |
因為上述代碼的第二個選擇表達式為1,所以前面沒有情況被選中就會選擇這種情況。這是HCL中一種指定默認情況的方法,幾乎所有情況表達式都以此結尾。
允許不互斥的選擇表達式使HCL變得更可讀,但實際的多路復用器信號必須互斥,因為它們要控制哪個輸入字應為輸出。要
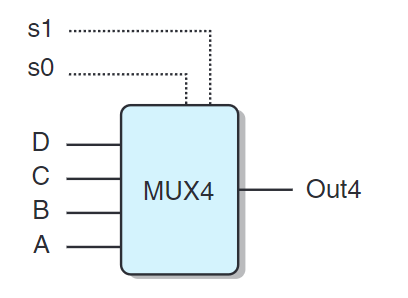
上圖是一個四路復用器,使用s1與s0從A、B、C、D中選擇。我們把s1與s2當作一個兩位的二進制數。使用HCL表示這個電路:
1 | word Out4 = [ |
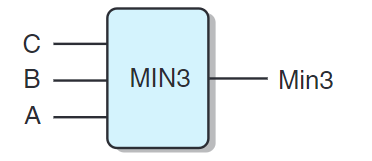
上圖實現尋找A、B與C最小值的功能。HCL如下:
1 | word Min3 = [ |
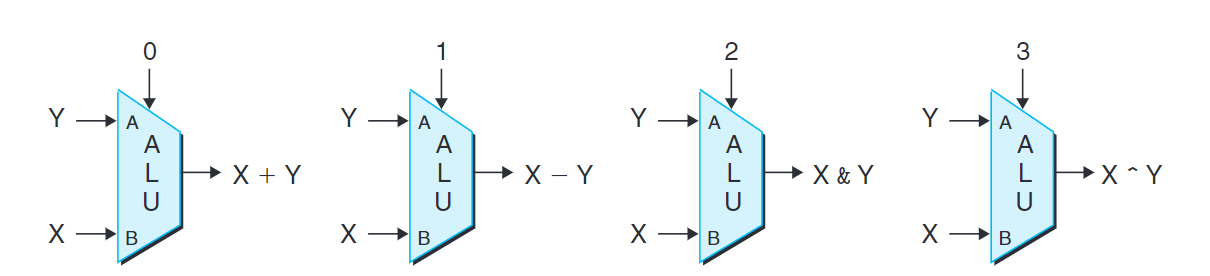
上圖為算數/邏輯單元 (ALU)。有三個輸入,根據控制輸入的值,電路會對數據輸入進行不同的運算或邏輯操作。注意減法順序,是B減去A,這是為了與subq的參數順序一致。
練習題
4.10
所有Bit equal換成xor,最後的AND換成OR連接NOT。
4.11
1 | word Min3 = [ |
4.12
1 | word Mid3 = [ |
集合關係
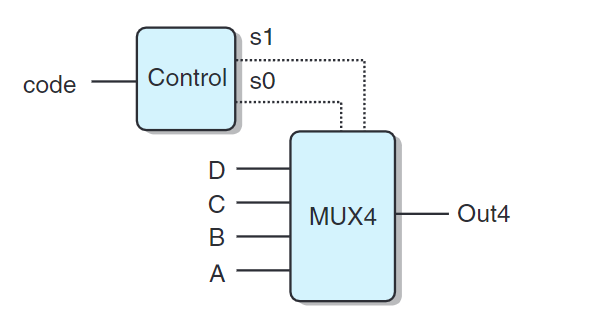
上圖的電路中利用信號code來控制輸出。根據code值,可以用相等測試來產生s1與s0。
1 | bool s1 = code == 2 || code == 3; |
另一種簡潔的表達方式為:
1 | bool s1 = code in {2, 3}; |
判斷集合關係的通用格式是:
這裡被測試的值$iex pr$和待匹配的值$iex pr{1} \sim iex pr{k}$都是整數表達式。
存儲器和時鐘
時鐘:週期性記號,決定甚麼時候把新值加載到設備中。
時鐘寄存器(簡稱寄存器):儲存單個位或字,由時鐘信號控制加載輸入值。
隨機訪問存儲器(簡稱內存):
- 虛擬內存
- 寄存器文件:
%rax ~ %r15
硬件寄存器:在硬件中,寄存器直接將他的輸入和輸出線連接到電路的其他部分。
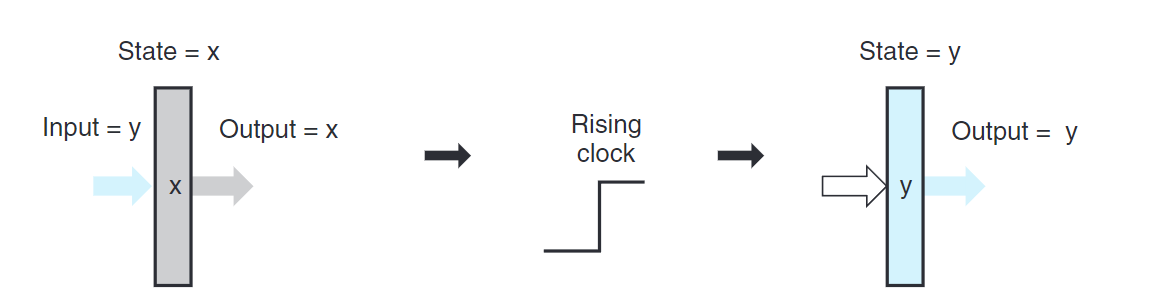
上圖展示了一次寄存器操作。只要信號保持在低電位,寄存器的值就不會改變。當時鐘變成高電位時,輸入信號就會加載到寄存器中,直到下一次時鐘上升沿。
軟件寄存器:在機器級編程中,寄存器代表的是CPU中可循址的字,這裡的地址是寄存器的ID。
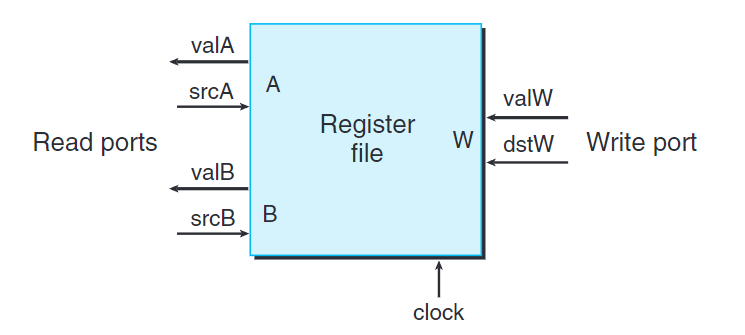
上圖為一個典型的寄存器文件架構。
寄存器文件中包含A、B兩個讀端口,和一個W寫端口。這樣一個多端口隨機訪問存儲器允許同時進行多個讀和寫操作。
當srcA被寫入一個寄存器地址,經過一段時間後,該寄存器中的值就會被保存到valA中。
向寄存器文件寫入值是由時鐘信號控制的,每次時鐘上升時,valW的值就會被寫入到dstW指向的寄存器中。
處理器有一個隨機訪問存儲器來存儲程序數據,如下圖所示。
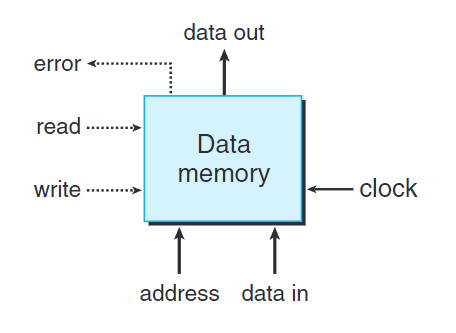
藉由write的零與一控制讀、寫。藉由error的零與一控制是否發生錯誤。
Y86-64的順序實現
此部分我們描述一個稱為SEQ(sequential)的處理器,在每個時鐘週期上,SEQ執行處裡一條完整指令所需的所有步驟。
將處理組織成階段
- 取指(fetch)
從內存中讀取指令字節。從指令中抽取出兩個部分,分別是icode(指令代碼)和ifun(指令功能)。還可能取出一個或兩個寄存器操作數指示符rA和rB。他還可能取出一個8字節常數valC。最後按順序方式計算當前指令的下一條指令的地址valP,即valP等於PC + 已取出指令的長度。 - 譯碼(decode)
從寄存器文件中讀出兩個操作數,得到值valA或/和valB。 - 執行(excute)
ALU執行指令指明的操作(根據ifun),得到一個值valE。此時也可能設置條件碼。對條件傳送指令來說,此階段會檢驗條件碼和傳送條件,若成立則更新目標寄存器。同樣,對跳轉指令來說,此時會決定是否跳轉。 - 訪存(memory)
將數據寫入內存或從內存中讀取值,讀取的值為valM。 - 寫回(write back)
此階段最多可寫兩個結果到寄存器文件中,即E端口和M端口。分別用來儲存ALU的計算結果valE和從內存中讀取的值valM。 - 更新PC(PC update)
1 | 1 0x000: 30f20900000000000000 | irmovq $9, %rdx |
上述代碼為Y86-64指令序列示例,我們會跟蹤這些指令通過各個階段的處理。
| 階段 | OPq rA, rB |
rrmovq rA, rB |
irmovq V, rB |
|---|---|---|---|
| 取指 | $icode: ifun$ $\leftarrow$ $M{1}[PC]$ $rA: rB \leftarrow M{1}[PC+1]$ $valP \leftarrow PC+2$ |
$icode: ifun$ $\leftarrow$ $M{1}[PC]$ $rA: rB \leftarrow M{1}[PC+1]$ $valP \leftarrow PC+2$ |
$icode: ifun$ $\leftarrow$ $M{1}[PC]$ $rA: rB \leftarrow M{1}[PC+1]$ $valC \leftarrow M_{8}[PC+2]$ $valP \leftarrow PC+10$ |
| 譯碼 | $valA \leftarrow R[rA]$ $valB \leftarrow R[rB]$ |
$valA \leftarrow R[rA]$ | |
| 執行 | $valE \leftarrow valB \ OP \ valA$ $Set \ CC$ |
$valE \leftarrow 0 + valA$ | $valE \leftarrow 0 + valC$ |
| 訪存 | |||
| 寫回 | $R[rB] \leftarrow valE$ | $R[rB] \leftarrow valE$ | $R[rB] \leftarrow valE$ |
| 更新PC | $PC \leftarrow valP$ | $PC \leftarrow valP$ | $PC \leftarrow valP$ |
上表給出對OPq、rrmovq、irmovq類型指令所需要的處理。符號$M{1}[x]$表示讀取x處1字節,$M{8}[x]$表示讀取x處8字節。
注意:表達式valB OP valA的順序與Y86-64和x86-64的習慣是一樣的。
| 階段 | OPq rA, rB |
subq %rdx, %rbx |
|---|---|---|
| 取指 | $icode: ifun$ $\leftarrow$ $M{1}[PC]$ $rA: rB \leftarrow M{1}[PC+1]$ $valP \leftarrow PC+2$ |
$icode: ifun$ $\leftarrow$ $M{1}[0x014] = 6:1$ $rA: rB \leftarrow M{1}[0x015] = 2:3$ $valP \leftarrow 0x016$ |
| 譯碼 | $valA \leftarrow R[rA]$ $valB \leftarrow R[rB]$ |
$valA \leftarrow R[\%rdx]=9$ $valB \leftarrow R[\%rbx]=21$ |
| 執行 | $valE \leftarrow valB \ OP \ valA$ $Set \ CC$ |
$valE \leftarrow 21-9=12$ $ZF \leftarrow 0,SF\leftarrow 0,OF\leftarrow 0$ |
| 訪存 | ||
| 寫回 | $R[rB] \leftarrow valE$ | $R[\%rbx] \leftarrow 12$ |
| 更新PC | $PC \leftarrow valP$ | $PC \leftarrow 0x016$ |
上表跟蹤了subq的指令執行。
| 階段 | pushq rA |
popq rA |
|---|---|---|
| 取指 | $icode: ifun$ $\leftarrow$ $M{1}[PC]$ $rA: rB \leftarrow M{1}[PC+1]$ $valP \leftarrow PC+2$ |
$icode: ifun$ $\leftarrow$ $M{1}[PC]$ $rA: rB \leftarrow M{1}[PC+1]$ $valP \leftarrow PC+2$ |
| 譯碼 | $valA \leftarrow R[rA]$ $valB \leftarrow R[\%rsp]$ |
$valA \leftarrow R[\%rsp]$ $valB \leftarrow R[\%rsp]$ |
| 執行 | $valE = valB - 8$ | $valE = valB + 8$ |
| 訪存 | $M_{8}[valE] \leftarrow valA$ | $valM = M_{8}[valA]$ |
| 寫回 | $R[\%rsp] \leftarrow valE$ | $R[\%rsp] \leftarrow valE$ $R[rA] \leftarrow valM$ |
| 更新PC | $PC \leftarrow valP$ | $PC \leftarrow valP$ |
上表給出pushq和popq指令的處理流程。
| 階段 | jxx Dest |
call Dest |
ret |
|---|---|---|---|
| 取指 | $icode: ifun$ $\leftarrow$ $M{1}[PC]$ $valC \leftarrow M{8}[PC+1]$ $valP \leftarrow PC+9$ |
$icode: ifun$ $\leftarrow$ $M{1}[PC]$ $valC \leftarrow M{8}[PC+1]$ $valP \leftarrow PC+9$ |
$icode: ifun$ $\leftarrow$ $M_{1}[PC]$ $valP \leftarrow PC+1$ |
| 譯碼 | $valB \leftarrow M[\%rsp]$ |
$valA \leftarrow M[\%rsp]$ $valB \leftarrow M[\%rsp]$ |
|
| 執行 | $Cnd \leftarrow Cond(CC, ifun)$ |
$valE\leftarrow valB-8$ | $valE = valB + 8$ |
| 訪存 | $M_{8}[valE]\leftarrow valP$ | $valM\leftarrow M_{8}[valA]$ | |
| 寫回 | $R[\%rsp] \leftarrow valE$ | $M[\%rsp] \leftarrow valE$ | |
| 更新PC | $PC\leftarrow Cnd ? valC : valP$ | $PC \leftarrow valC$ | $PC \leftarrow valM$ |
上表給出跳轉、call和ret的處理流程。
練習題
4.13
| 階段 | irmovq V, rB |
irmovq $128, %rsp |
|---|---|---|
| 取指 | $icode: ifun$ $\leftarrow$ $M{1}[PC]$ $rA: rB \leftarrow M{1}[PC+1]$ $valC \leftarrow M_{8}[PC+2]$ $valP \leftarrow PC+10$ |
$icode: ifun$ $\leftarrow$ $M{1}[0x016] = 3:0$ $rA: rB \leftarrow M{1}[0x017] = f:4$ $valC \leftarrow M_{8}[0x018] = 128$ $valP \leftarrow 0x020$ |
| 譯碼 | ||
| 執行 | $valE \leftarrow 0 + valC$ | $valE \leftarrow 128$ |
| 訪存 | ||
| 寫回 | $R[rB] \leftarrow valE$ | $R[\%rsp] = 128$ |
| 更新PC | $PC \leftarrow valP$ | $PC \leftarrow 0x020$ |
4.14
略,查代碼就好,很簡單留給你們試試。
4.15
壓入原始%rsp值,與4.7中確認的一樣。
4.16
彈出原始%rsp值,與4.8中確認一樣。
4.17
| 階段 | cmovXX rA, rB |
|---|---|
| 取指 | $icode: ifun$ $\leftarrow$ $M{1}[PC]$ $rA: rB \leftarrow M{1}[PC+1]$ $valC \leftarrow M_{8}[PC+2]$ |
| 譯碼 | $valA \leftarrow R[rA]$ $valB \leftarrow R[rB]$ |
| 執行 | $valE \leftarrow 0+valA$ $Cnd \leftarrow Cond(C C, ifun)$ |
| 訪存 | |
| 寫回 | $R[rB] \leftarrow Cnd?valE:valB$ |
| 更新PC | $PC \leftarrow valP$ |
4.18
略,查查看就知道了。
SEQ硬件結構
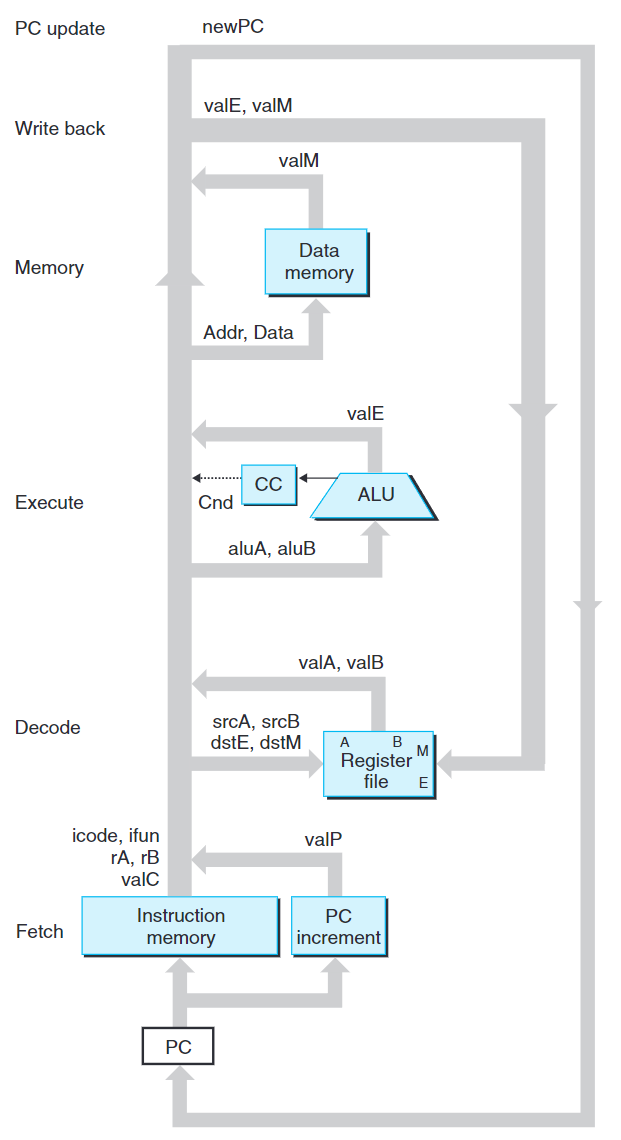
上圖為SEQ的抽象視圖,下圖為完整的SEQ硬件結構。
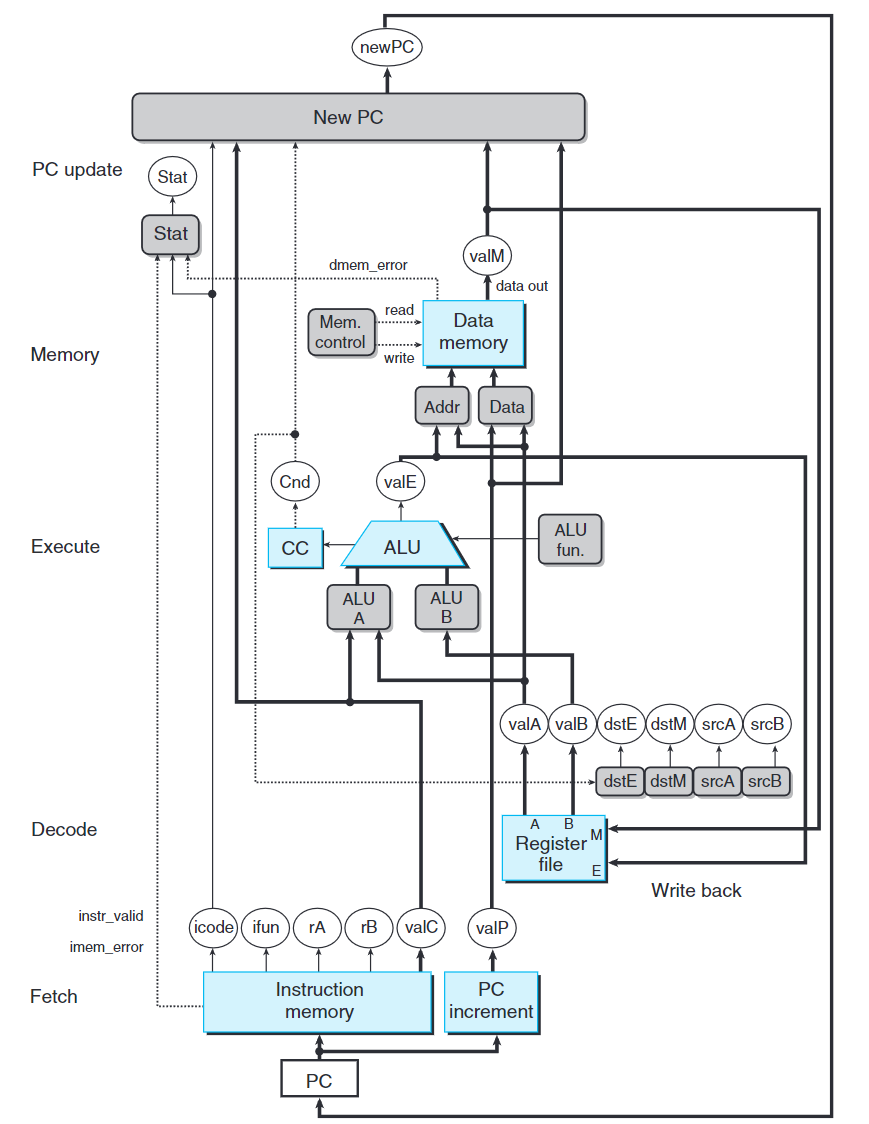
- 白色方框表示時鐘寄存器。PC是SEQ中唯一的時鐘寄存器。
- 淺藍色方框表示硬件單元。
- 灰色圓角矩形表示控制邏輯塊,這些塊用來從一組信號源中進行選擇或者計算一些布爾函數。
- 白色圓圈標示路線名稱,非硬件單元。
- 最粗的線表示寬度為字長的數據,這種線每條代表一簇64根線,將一個字從硬件的一個部分傳遞到另一部份。
- 較細的線表示寬度為字節或更窄的數據,這種線每條表示一簇4根或8根線。
- 虛線表示單個位的連接,代表芯片上單元與塊之間傳遞的控制值。
SEQ的時序
SEQ的實現包含組合邏輯和時鐘寄存器(程序計數器、條件碼寄存器)與隨機訪問存儲器(寄存器文件、數據內存)。
組合邏輯不須要任何時序控制,只要輸入變化了,值就通過邏輯門網絡傳播。
而剩下的存儲器設備我們需要對其時序進行明確的控制。
對於Y86-64,我們遵循以下原則:
從不回讀。
處理器從不需要為了執行一條指令而去讀由該指令更新了的狀態。
比如在我們的設計中,pushq %rsp會將%rsp的原值壓入棧頂。若我們壓入的是%rsp+8的話,代表為了執行該操作我們需要讀取寄存器文件中更新過的棧指針,這與我們的原則相悖。
我們使用以下代碼來跟蹤SEQ的運行週期。
1 | 0x000: irmovq $0x100,%rbx # %rbx <-- 0x100 |
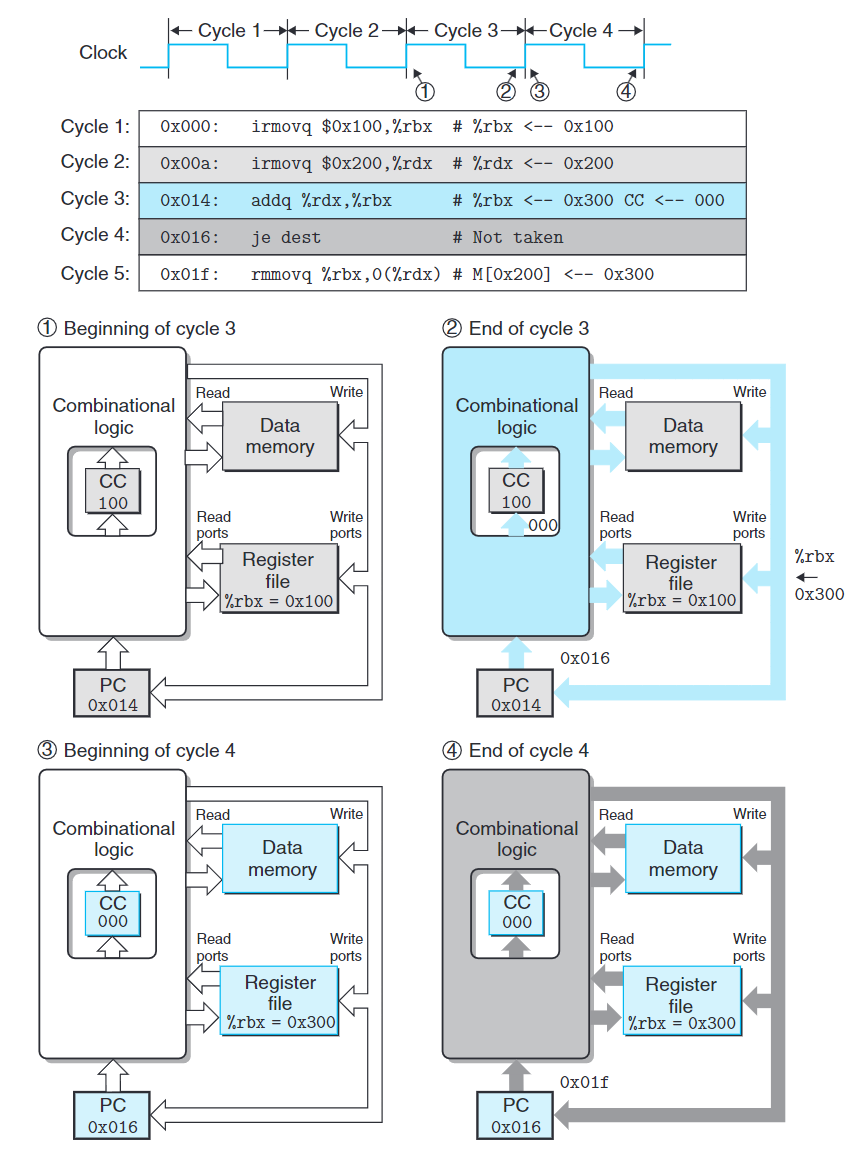
- 週期3開始時:狀態單元保持的是第二條
irmovq指令更新過的狀態,該指令用淺灰色表示,而組合邏輯用白色表示,說明他還沒來的即對變化了的狀態做響應。時鐘週期開始時,0x014載入PC中,取出和處理addq指令。 - 週期3結束時:值沿著邏輯電路流動。所有存儲器準備更新值。
- 週期4開始時:更新PC。存儲器遇到時鐘上升沿,更新由周期3結束時提供的值。同時取出
je並處理。 - 週期4結束時:組合邏輯根據
je指令更新,PC待更新的值也計算結束。但所有存儲器保持原值,等待下個時鐘上升沿(下個週期)後更新。
SEQ階段的實現
下表事先列出我們常用的常數值。
| 名稱 | 值(hex) | 含意 |
|---|---|---|
IHALT |
0 | halt指令的偽代碼 |
INOP |
1 | nop指令的偽代碼 |
IRRMOVQ |
2 | rrmovq指令的偽代碼 |
IIRMOVQ |
3 | irmovq指令的偽代碼 |
IRMMOVQ |
4 | rmmovq指令的偽代碼 |
IMRMOVQ |
5 | mrmovq指令的偽代碼 |
IOPQ |
6 | 整數運算指令的代碼 |
IJXX |
7 | 跳轉指令的代碼 |
ICALL |
8 | call指令的代碼 |
IRET |
9 | ret指令的代碼 |
IPUSHQ |
A | pupshq指令的代碼 |
IPOPQ |
B | popq指令的代碼 |
FNONE |
0 | 默認功能碼 |
RRSP |
4 | %rsp的寄存器ID |
RNONE |
F | 表明沒有寄存器文件訪問 |
ALUADD |
0 | 加法運算的功能 |
SAOK |
1 | 正常操作狀態碼 |
SADR |
2 | 地址異常狀態碼 |
SINS |
3 | 非法指令異常狀態碼 |
SHLT |
4 | halt狀態碼 |
取指階段
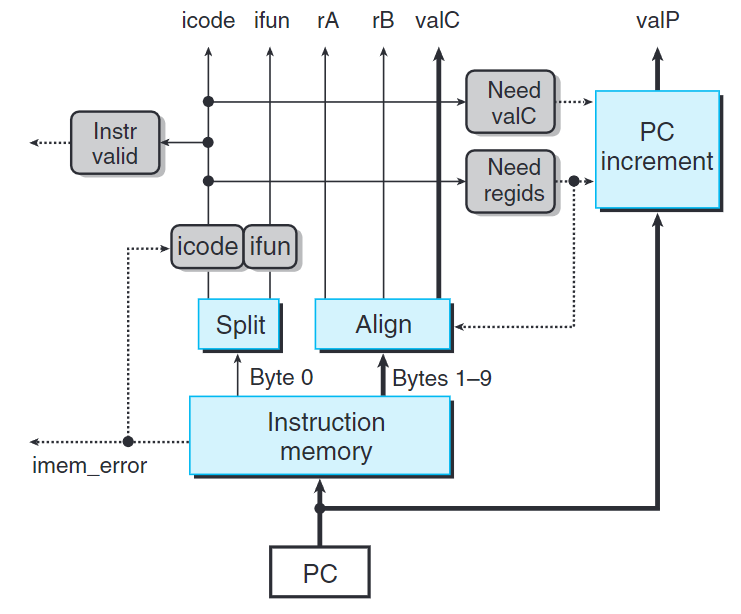
此階段會從以PC(字節0)開始處讀取10個字節。第一個字節被解釋為指令字節,(標為Split的單元)分為兩個4位數。
我們可以計算三個一位的信號:
instr_valid:該字節是否是合法的指令need_regids:該指令是否需要寄存器need_valC:該指令是否需要常數參數
由此我們可以設計need_regids的HCL描述:
1 | bool need_regids = icode in { |
need_valC的HCL描述:
1 | bool need_valC = icode in { |
標號為Align的單元會處理剩下的9個字節。當need_regids為1時,字節1被分開裝入rA與rB中。否則這兩個字段被設為0xF(RNONE)。根據信號need_regids與need_valC的值,要麼根據字節$1\sim 8$來產生valC,要麼根據字節$2\sim 9$來產生。
PC_increment單元根據當前PC與need_regids和need_valC產生valP。
譯碼和寫回階段
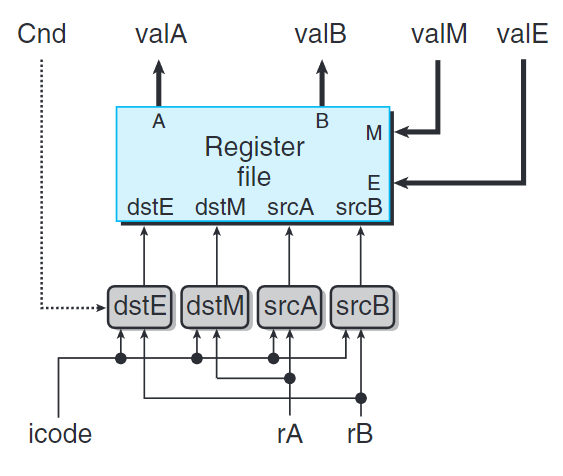
對於valA與valB的產生規則,我們需要參考前述表格的”譯碼”階段。
1 | word srcA = [ |
1 | word srcB = [ |
dstE表明寫端口E的目的寄存器,計算出來的valE存放在此處。
下方處理dstE的代碼暫時忽略條件移動指令。我們查看執行階段時,會重新審視這個信號,正確實現條件傳送。
1 | // Warning: Conditional move not implemented correctly here |
dstM表明寫端口M的目的寄存器,從內存中讀出的valM會放在此處。
1 | word dstM = [ |
練習題
4.22
M優先度更高 (輸出原始值)
執行階段
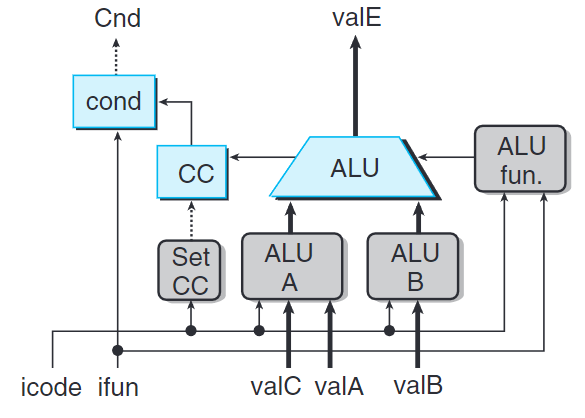
ALU單元根據alufun信號設置,對輸入aluA和aluB執行運算。
在計算中aluB在前,aluA在後。這樣可以保證subq指令是valB減去valA。
1 | word aluA = [ |
1 | word aluB = [ |
通常ALU在執行階段做加法器使用,不過,對於OPq指令,我們希望他使用指令ifun字段中編碼的操作。
1 | word alufun = [ |
執行階段還包含條件碼寄存器,在執行OPq時設置條件碼。
1 | bool set_cc = icode in { IOPQ }; |
標號為cond的硬件單元會根據條件碼和功能碼來確定是否進行條件分支或者條件數據傳輸。他產生信號Cnd,用於設置dstE或下一個PC。
1 | word dstE = [ |
訪存階段
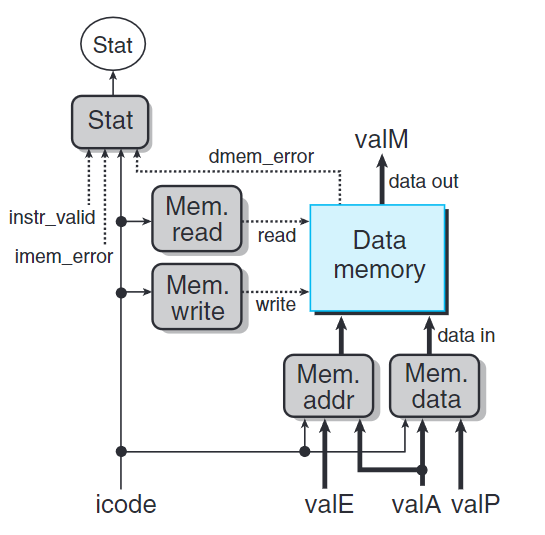
此階段讀或寫程序數據到內存中。兩個控制塊產生內存地址和內存輸入數據(為寫操作),另外兩個塊產生控制該執行讀還是寫操作的控制信號。當執行讀操作時,數據內存產生值valM。
mem_addr為(讀寫)操作的目標地址,mem_data為(讀寫)操作的數據。
1 | word mem_addr = [ |
1 | word mem_data = [ |
1 | bool mem_read = icode in { IMRMOVQ, IPOPQ, IRET }; |
1 | bool mem_write = icode in { IRMMOVQ, IPUSHQ, ICALL }; |
1 | word stat = [ |
更新PC階段
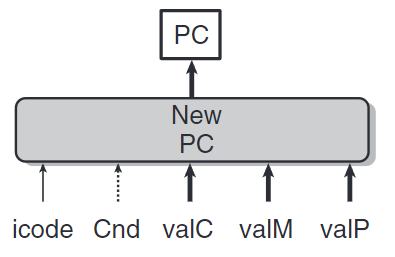
1 | word new_pc = [ |
SEQ小節
以上就是Y86-64處理器的一個完整設計。SEQ唯一的問題就是速度慢,時鐘必須非常慢才能讓信號在一個周期內傳播所有階段。此方法不能充分利用硬件單元,因為每個單元只在整個時鐘周期的一部份時間內才被使用。
流水線的通用原理
流水線化的系統中,待執行的任務被劃分成了若干個獨立的階段,允許多個階段同時運行。
流水線化的重要特性就是提高系統的吞吐量(throughput),但也會輕微的增加延遲(latency),就是一次完整流程所需的時間。
計算流水線
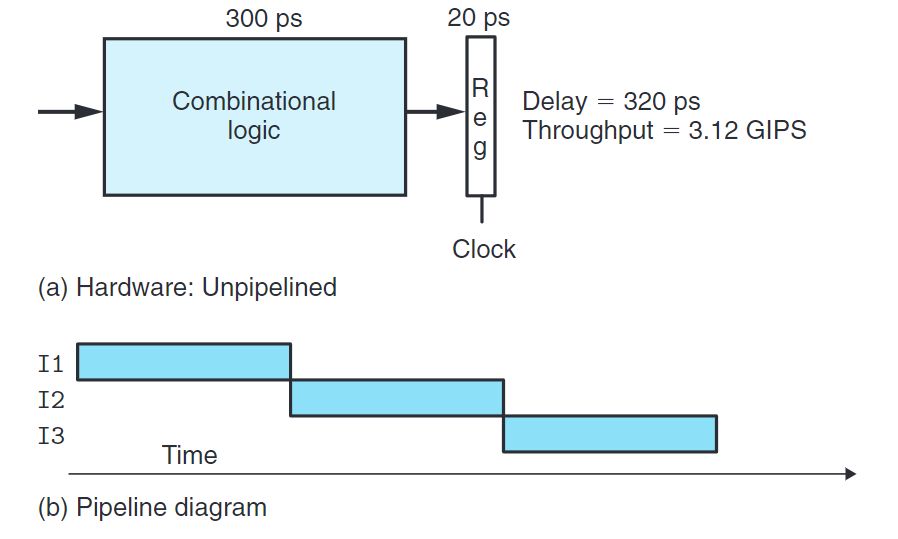
上圖為一個非流水線畫的硬件系統。圖b稱流水線圖(pipeline diagram)。在現代邏輯設計中,電路延遲以微微秒或皮秒(picosecond, ps),也就是$10^{-12}$秒為單位計算。從頭到尾執行一條指令所需的時間稱延遲(latency)。
若組合邏輯需要300ps,加載寄存器需要20ps,則可以計算此系統的最大吞吐量:
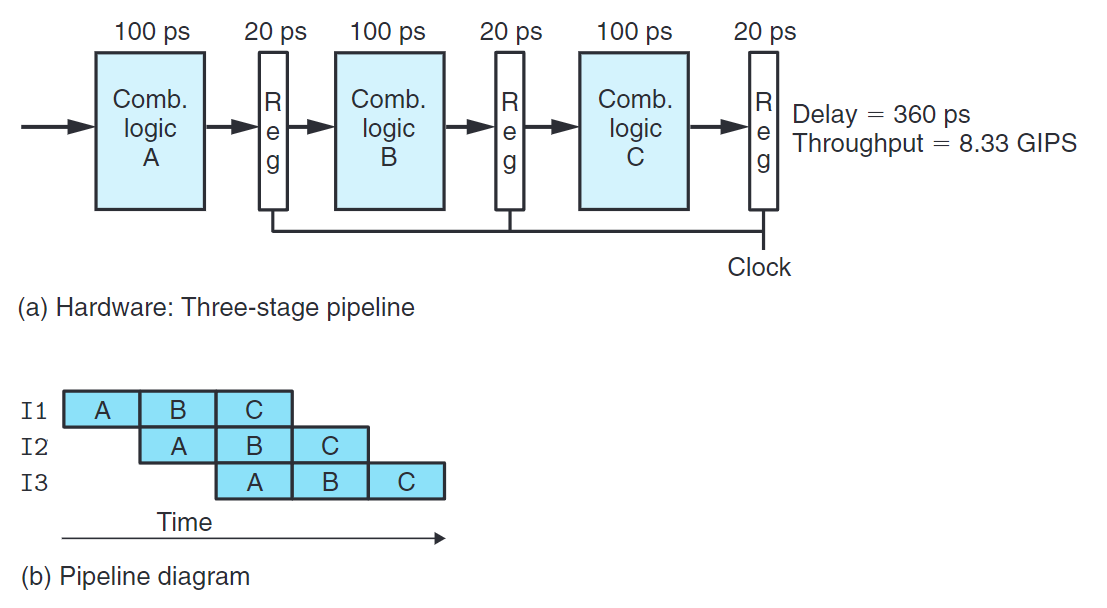
上圖是一個三階段流水線化的計算硬件,個階段間的寄存器稱流水線寄存器(pipeline register)。
更改後的系統吞吐量大約為$8.33 \ GIPS$,代價是增加了一些硬件,以及延遲少量增加。
延遲變大由增加的流水線寄存器的時間開銷。
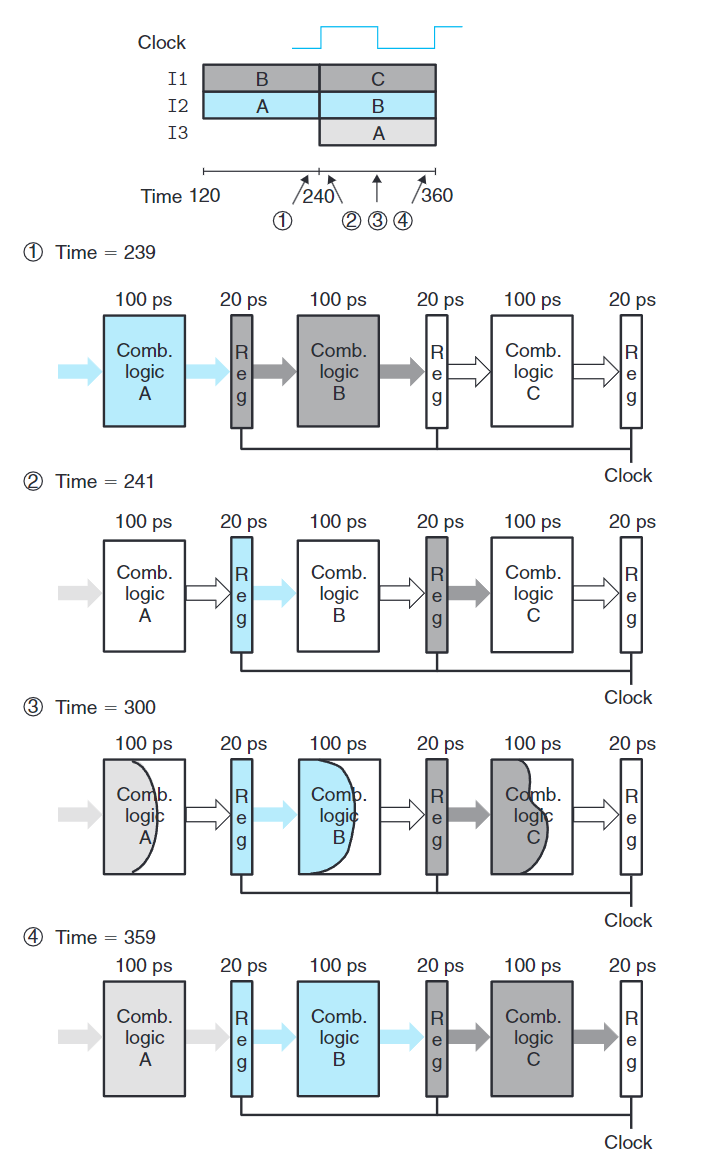
流水線操作的詳細說明
流水線的侷限性
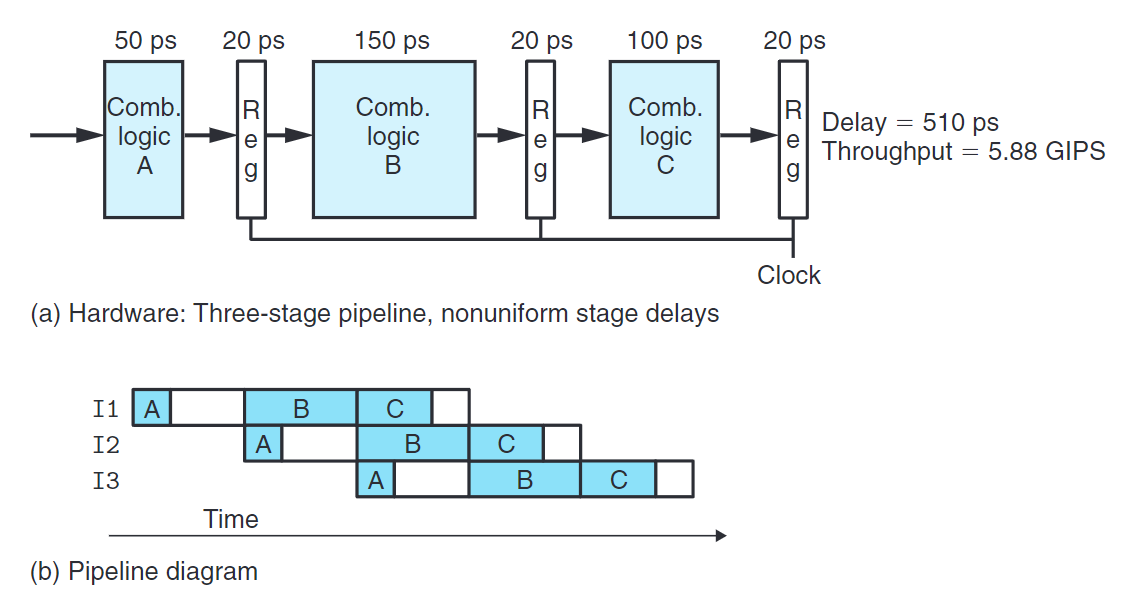
不一致的劃分
在前面展示的系統中,每階段的延遲(100ps)一致。不過實際設計中,可能會出現每階段延遲不同的情況,而運行時鐘的速率是由最慢階段的延遲控制的,導致各階段出現長度不一的空閒。
流水線過深,收益下降
流水線的深度即階段個數,過深的流水線深度會增加通過流水線寄存器的延遲和。
為提高時鐘平率,現代處理器採用很深的(15或更多階段)流水線。
練習題
4.28
A
CD間
B
BC間、DE間
C
AB間、CD間、DE間
D
五個階段
4.29
略
帶反饋的流水線系統
數據相關(data dependency):之後的數據依賴於先前的數據。
控制相關(control dependency):跳轉或ret指令導致下條指令的PC不確定。
Y86-64的流水線實現
SEQ+:重新安排計算階段
SEQ+就是將更新PC階段放在時鐘開始時執行的,更符合流水線設計的SEQ架構。
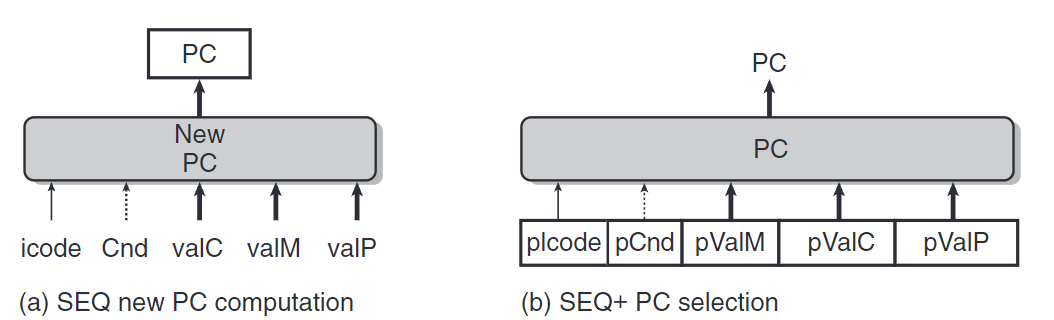
(a): SEQ,PC計算發生在時鐘周期結束的時候。根據當前時鐘周期內計算出的信號計算PC值。
(b): SEQ+,PC計算發生在時鐘周期開始時。我們需要創建狀態寄存器來保存上一條指令計算出的信號。當新的時鐘周期開始時,這些信號通過與SEQ同樣的邏輯計算PC。
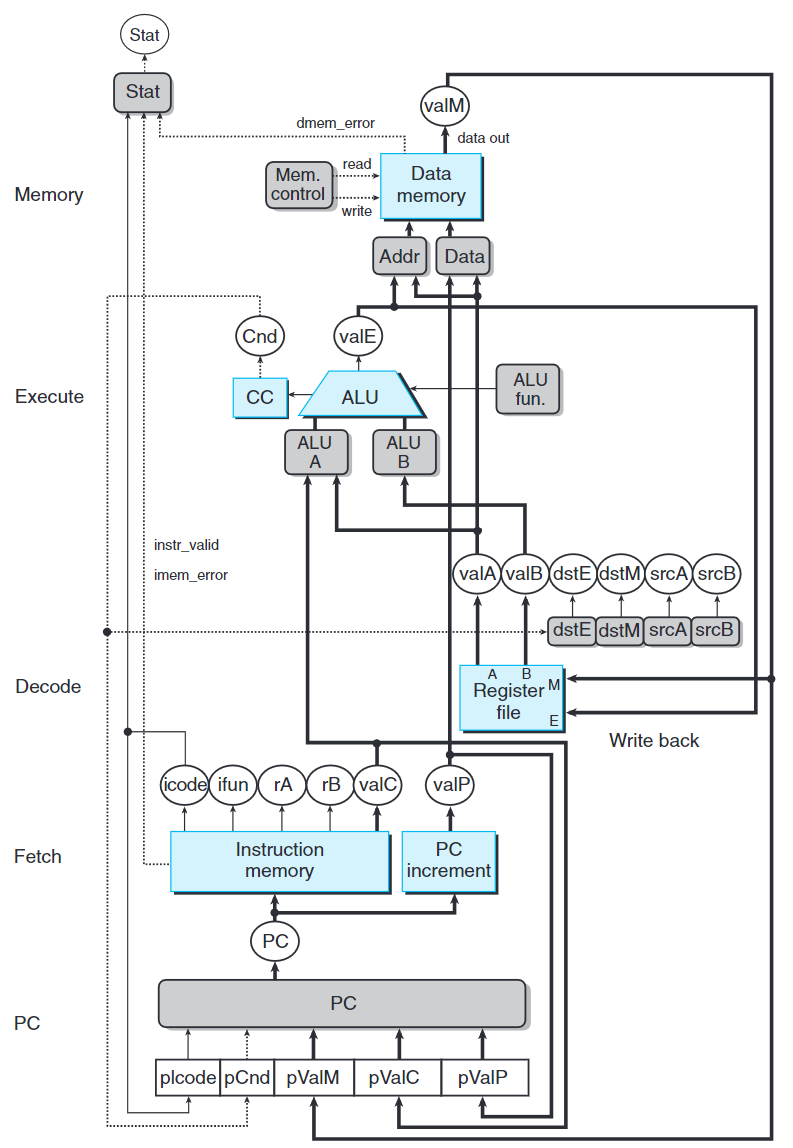
上圖給出SEQ+硬件更為詳細的說明。PC邏輯從時鐘週期結束處移到時鐘週期開始處。
SEQ到SEQ+中對狀態單元的改進稱電路重定時(circuit retiming)。重定時改變了一個系統的狀態表示,但是不改變他的邏輯行為。通常用他來平衡一個流水線系統中各個階段間的延遲。
插入流水線寄存器
我們需要在SEQ+的各個階段間插入流水線寄存器,並對信號重新排列,得到新的PIPE$-$處理器。
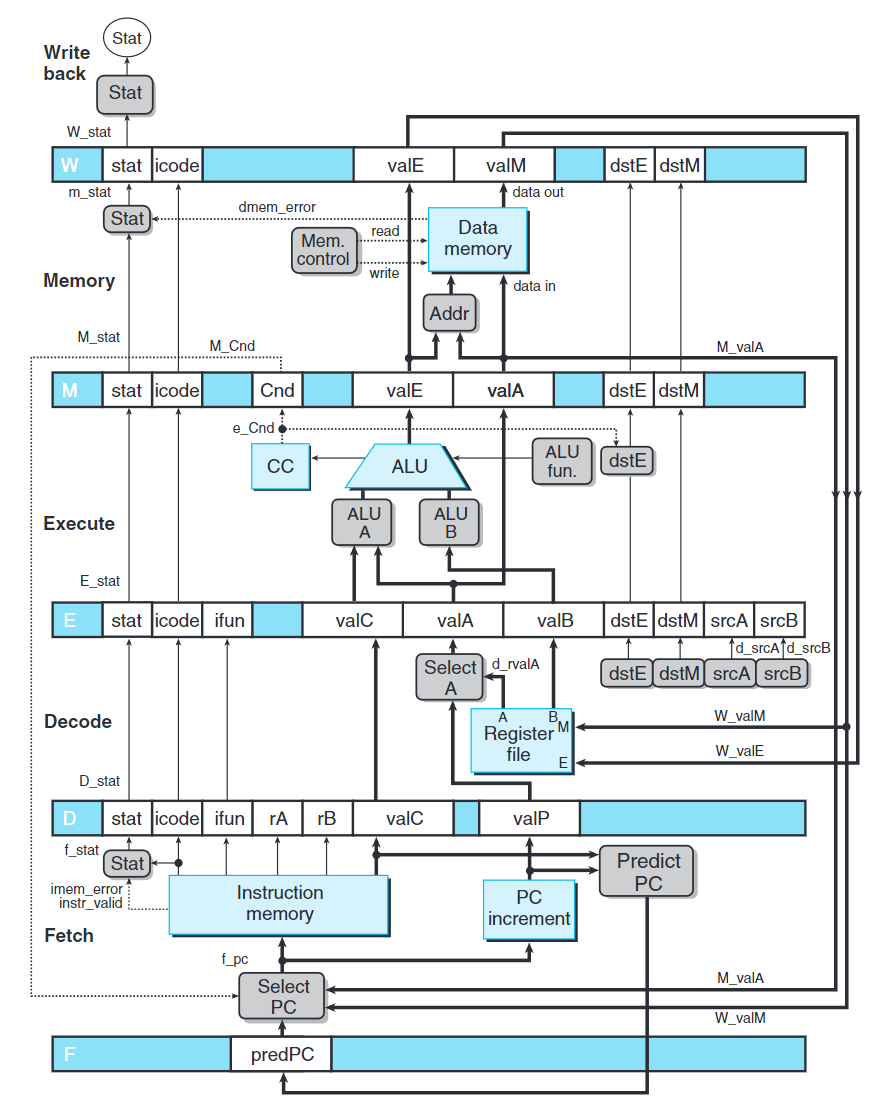
上圖是PIPE$-$的抽象結構。流水線寄存器在圖中以黑色方框表示,每個寄存器包括不同字段,以白色方框表示。
流水寄存器如下標示:
F: Fetch
D: Decode
E: Execute
M: Memory
W: Write back
對信號進行重新排列和標號
流水線化設計中,我們需要保存不同指令的同名信號。例如在PIPE$-$中我們需要保存4個Stat信號。
我們為信號的命名規則如下:
大寫流水線寄存器做前綴:流水線寄存器
小寫流水線寄存器做前綴:在某階段剛被計算出來的信號
M_stat: 流水線寄存器M的狀態碼字段
m_stat: 訪存階段中由控制邏輯塊產生的狀態信號
我們注意到PIPE$-$中標號為Select A的塊,他會從流水線寄存器D的valP或寄存器文件A端口選擇一個。
這麼做是為了減少傳送給E和M的狀態數量。
因為只有call在訪存階段需要valP的值,只有跳轉在執行階段需要valP的值。而剛好這兩種指令不需要在寄存器文件中讀取值,所以我們可以合併此二信號。
預測下一個PC
流水線化設計希望每個周期都有一條新指令進入執行階段並完成,可惜的是,如果取出的指令是條件分支,需要等指令通過執行階段才能確定是否選擇分支。同樣,如果取出ret指令,則要等指令通過訪存階段才能確定返回地址。
對call和jmp來說,下一條指令的地址即常數字段valC。
通過預測PC的下一個值,多數情況下我們可以做到每個時鐘週期發射一條新指令。
猜測分支方向並取指的技術稱為分支預測。在此我們的策略是總是選擇(always taken)。其他還有從不選擇(never taken, NT)、反向選擇,正向不選擇(backward taken, forward not-taken, BTFNT)。
我們不預測ret的值,因為返回值幾乎是無限的。我們只是簡單的暫停處理新指令,直到ret通過寫回階段。
Select PC塊從三個值中選擇一個作為指令內存的地址:
- 預測的PC。
- 到達流水寄存器M且不選擇分支的指令->
valP的值(儲存在M_valA中)。 ret到達流水寄存器W時W_valM的值。
流水線冒險
相鄰指令間會出現以下問題:
- 數據相關
- 控制相關
這些相關可能會導致一些問題,我們稱冒險(hazard):
- 數據冒險(data hazard)
- 控制冒險(control hazard)
用暫停避免數據冒險
暫停(stalling) 是避免冒險的常用技術,暫停時,處理器會停止流水線中一條或多條指令,直到冒險條件不再被滿足。
讓一條指令停頓在譯碼階段,直到產生源操作數的指令通過寫回階段,這樣處理器就避免了一次冒險。
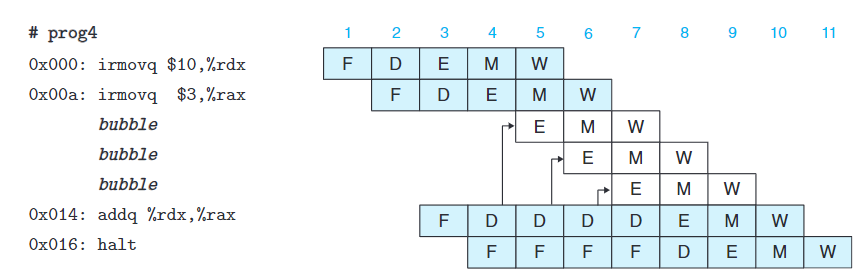
將addq阻塞在譯碼階段時,我們還需要將halt阻塞在取碼階段。
通過將PC保持不變就能做到,此時,會不斷對halt進行取指,直到暫停結束。
暫停技術可讓一組指令阻塞在所處的階段,但是允許其他指令繼續通過流水線。
在該指令本該執行的階段,我們插入氣泡(bubble)。氣泡就像nop,不會改變寄存器、內存、條件碼或程序狀態。
雖然這種機制容易實現,但是會導致流水線暫停三個周期,而且這種狀況十分常見,會嚴重降低吞吐量。
用轉發避免數據冒險
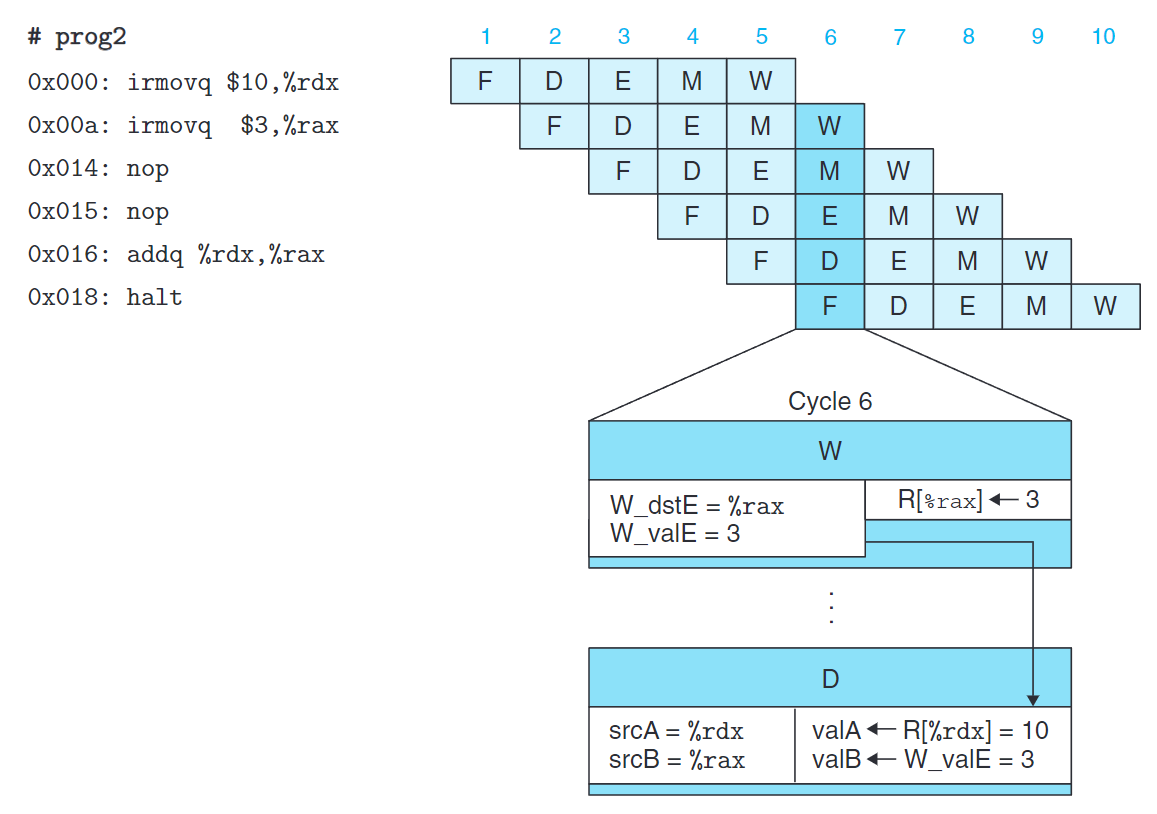
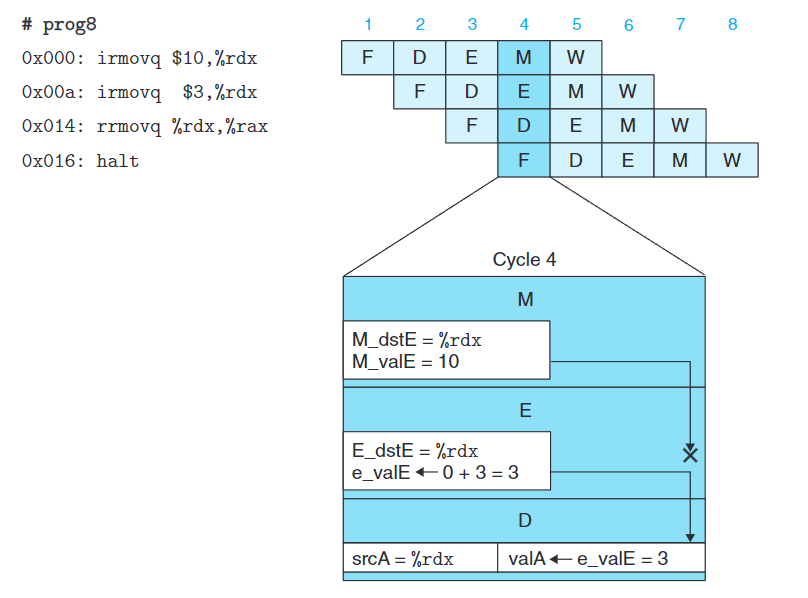
這裡我們關注週期6。此時,0x016處代碼需要將%rax的值作為valB,而0x00a處代碼正要將3寫回%rax。正常我們需要再等待一個週期(即下個時鐘上升沿使得寄存器被寫入)才能進行0x016處的譯碼階段。
這裡我們使用一個稱為數據轉發(data forwarding, 或簡稱轉發,有時稱為旁路(bypassing)) 的技術,直接將W_valE傳送到srcB中,就能避免暫停。
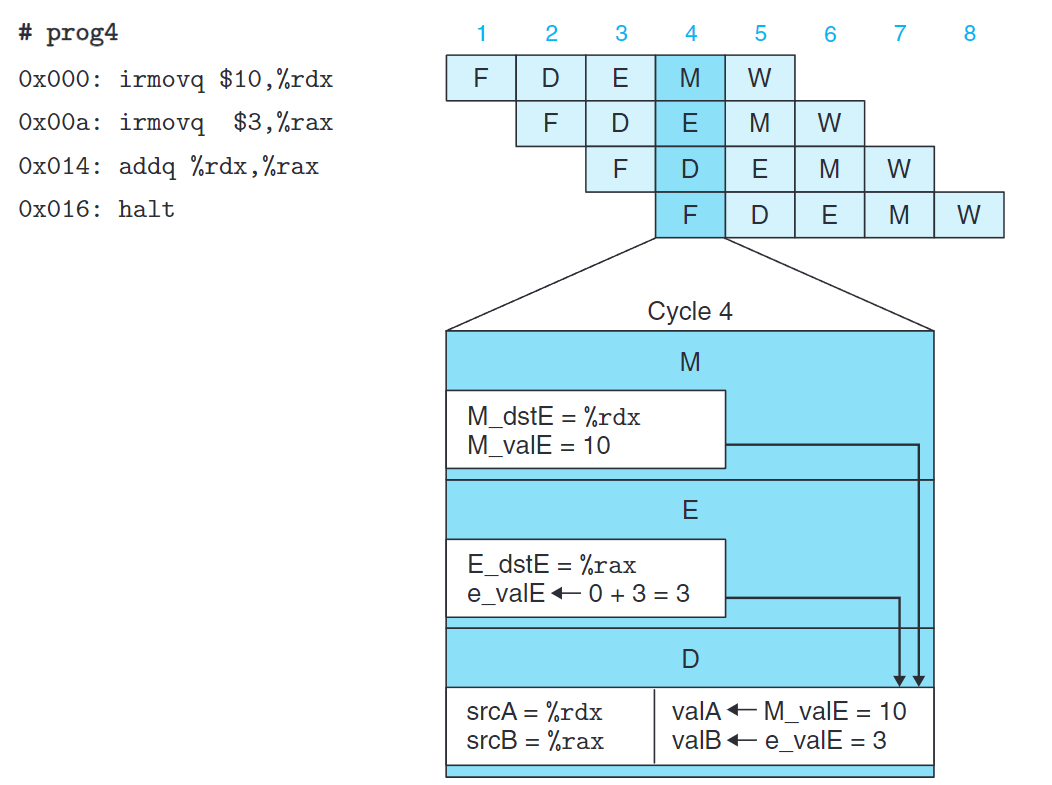
同樣,我們還可以直接轉發執行階段中ALU剛計算出的值(e_valE),如上圖所示。
綜上所述,我們其實有五個轉發源(e_valE, m_valM, M_valE, W_valM, W_valE)和兩個轉發目的(valA, valB)。
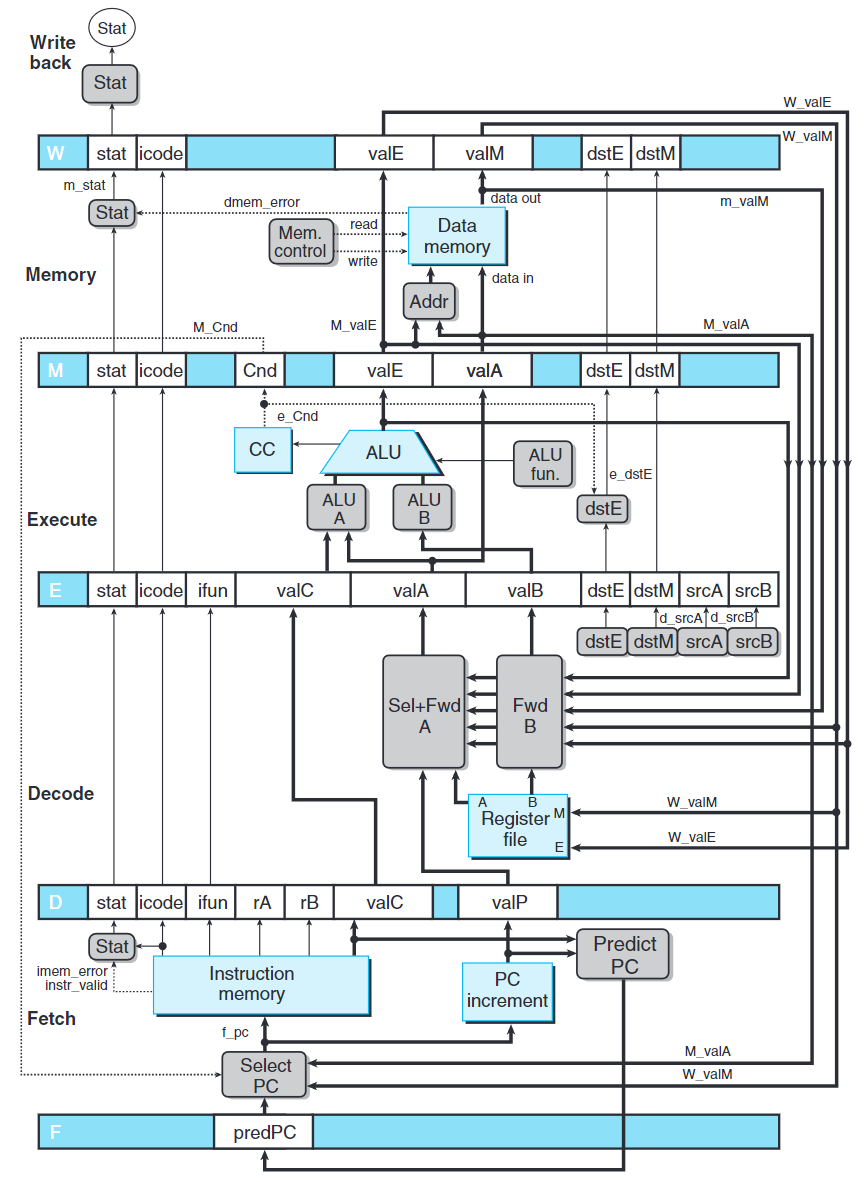
上圖是PIPE結構,為PIPE$-$的拓展。
Sel+Fwd A是Select A塊與轉發邏輯的結合,允許E_valA的值為valP、寄存器文件A讀出的值,或某個轉發過來的值。
Fwd B實現valB的轉發邏輯。
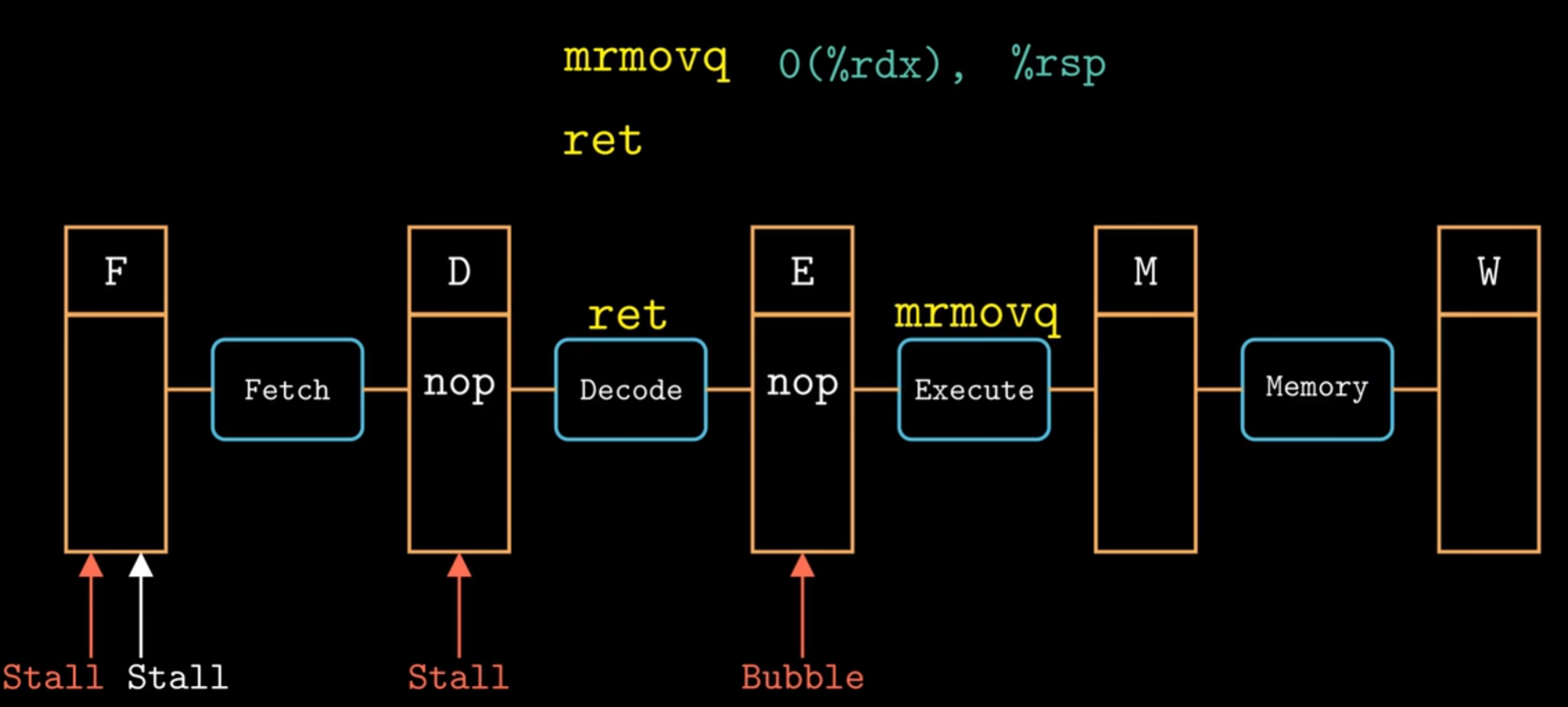
加載/使用數據冒險
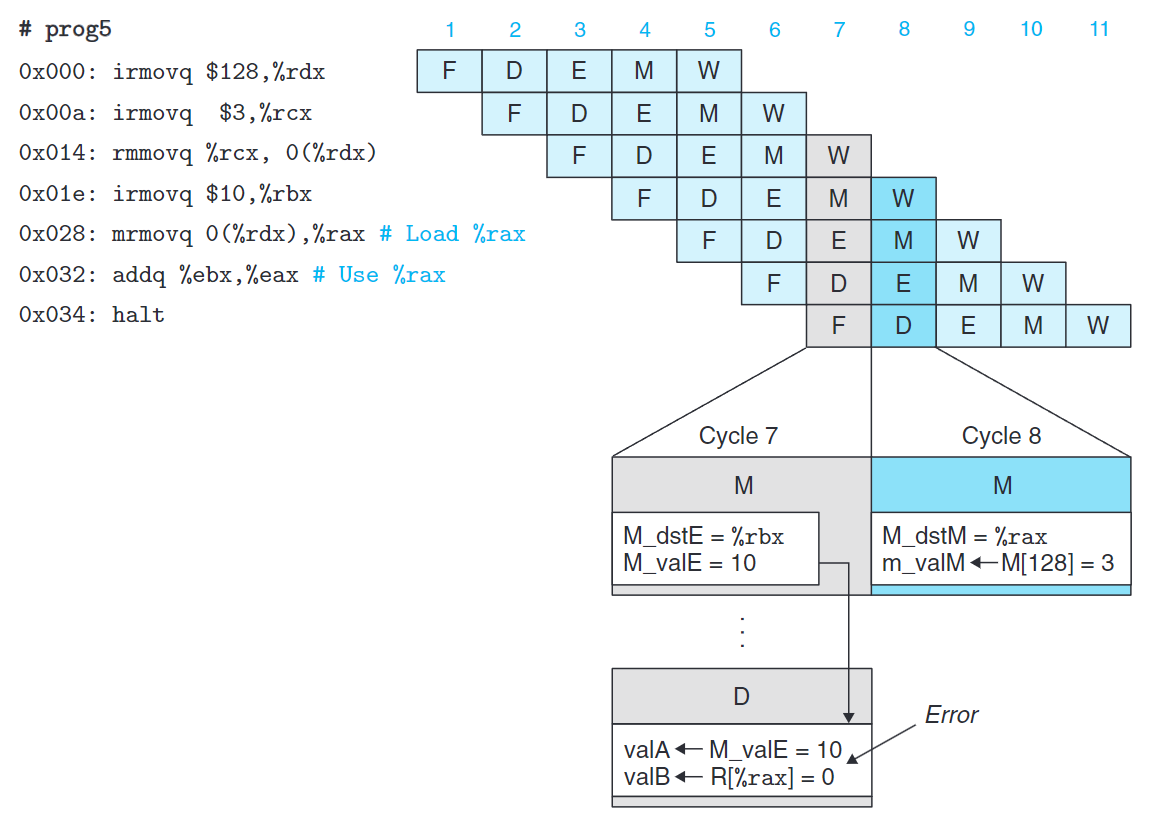
如上圖所示,位於0x028與0x032發生的加載/使用冒險(load/use hazard) 無法單純的使用轉發來解決。
關注週期7與8,0x028的訪存發生在0x032譯碼階段後,無法使用轉發來解決問題(除非可以回到過去)。
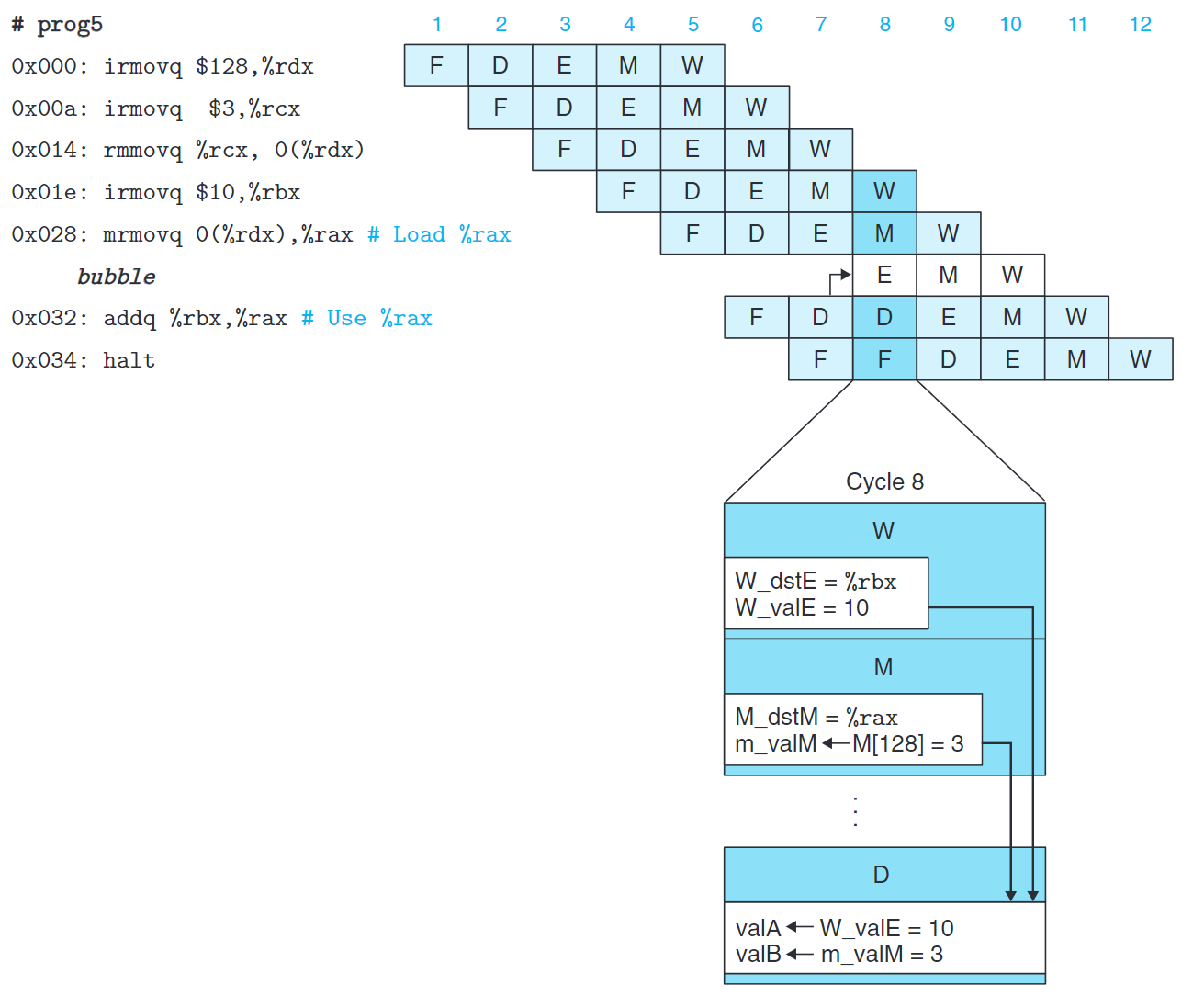
如上圖所示,我們使用暫停與轉發結合,就避免了加載/使用冒險。
這種用暫停來處理加載/使用冒險的方法稱為加載互鎖(load interlock)。加載互鎖和轉發技術結合起來幾乎可以處理所有可能類型的數據冒險。
避免控制冒險
當處理器無法根據取指確定下條指令的地址時,就會出現控制冒險。在我們的流水線化處理器中,控制冒險只會發生在ret和跳轉指令中。而且,後一種狀態只有在條件跳轉方向預測錯誤時才會造成麻煩。
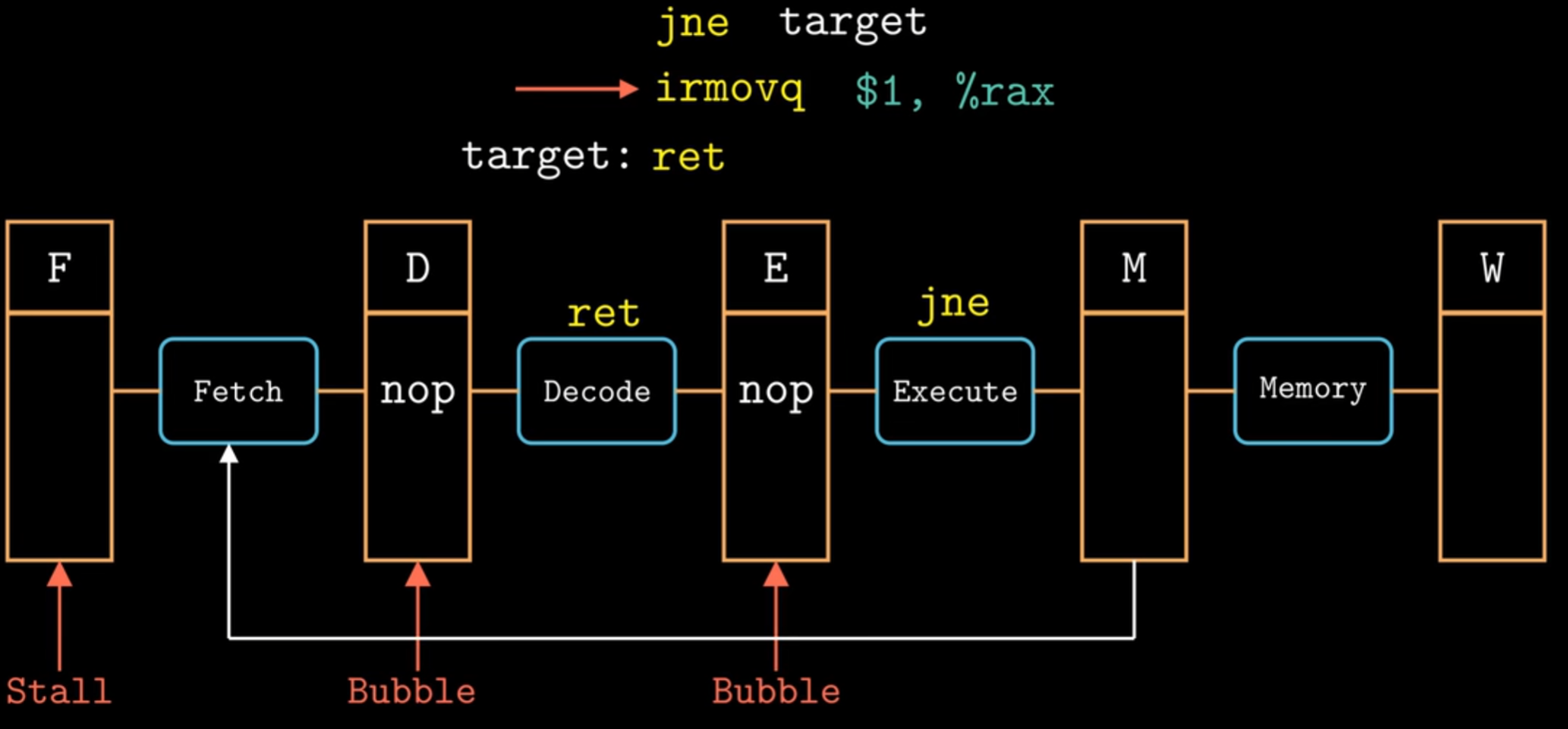
對於ret指令,考慮以下代碼:
1 | 0x000: irmovq stack,%rsp # Initialize stack pointer |
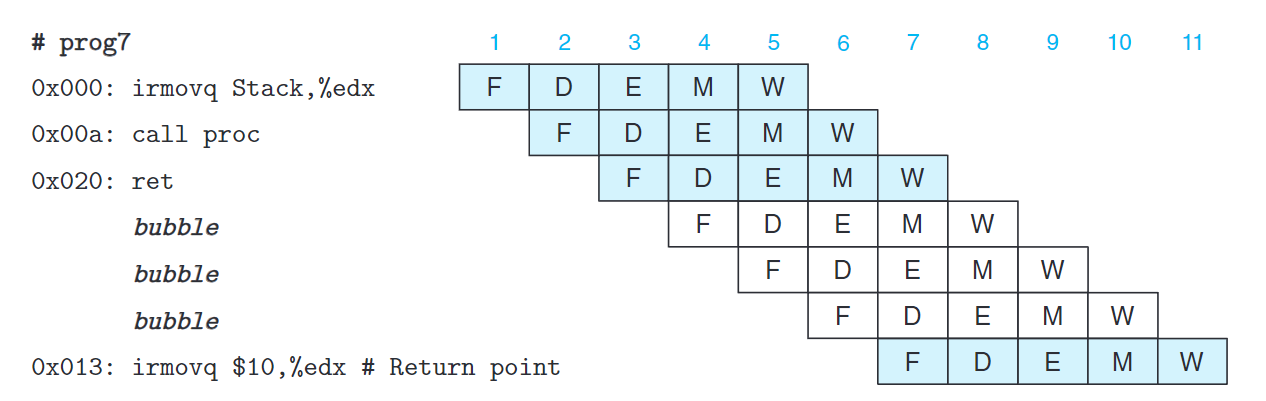
上圖給出我們希望流水線如何處理ret指令。我們要等待ret到達寫回階段才能知道下個PC,所以在流水線中插入三個氣泡。
要處理預測錯誤的分支,考慮以下代碼:
1 | 0x000: xorq %rax,%rax |
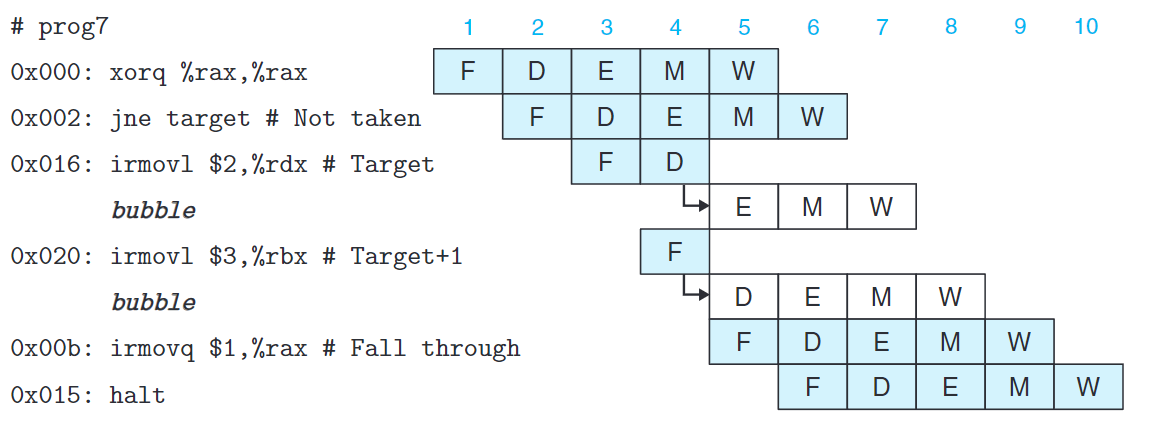
如上圖所示,遇到條件跳轉我們都會選擇跳轉。當條件跳轉指令執行到執行階段時,我們就可以確定預測的結果是否正確。
在prog7狀況下,我們預測錯誤。幸好這時預測錯誤的兩條指令還沒有導致程序員可見狀態發生改變(只有運行到執行階段才會發生這種狀況)。
此時我們只需要在兩條指令後面插入氣泡,就能取消(有時稱為指令排除(instruction squashing)) 預測錯誤的指令。唯一的缺點是浪費了兩個時鐘週期。
異常處理
我們的指令集體系結構包括三種異常:
halt指令- 非法指令或非法功能碼組合
- 取指或數據讀寫試圖訪問一個非法地址
我們將導致異常的指令稱作異常指令(excepting instruction)。其中,在非法指令的情況中,沒有實際的異常指令。
異常處理包括以下三個細節:
- 同時有多條指令引發異常
由流水線中最深指令引發的異常優先級最高 - 條件分支時預測的下一個PC處指令觸發異常,但分支預測錯誤
取消該指令 - 某指令觸發異常,其後的指令在異常指令完成前改變部分程序員可見狀態
處於訪存或寫回階段的指令產生異常時,流水線控制邏輯需禁止更新條件碼寄存器或數據內存。
PIPE各階段的實現
PC選擇和取指階段
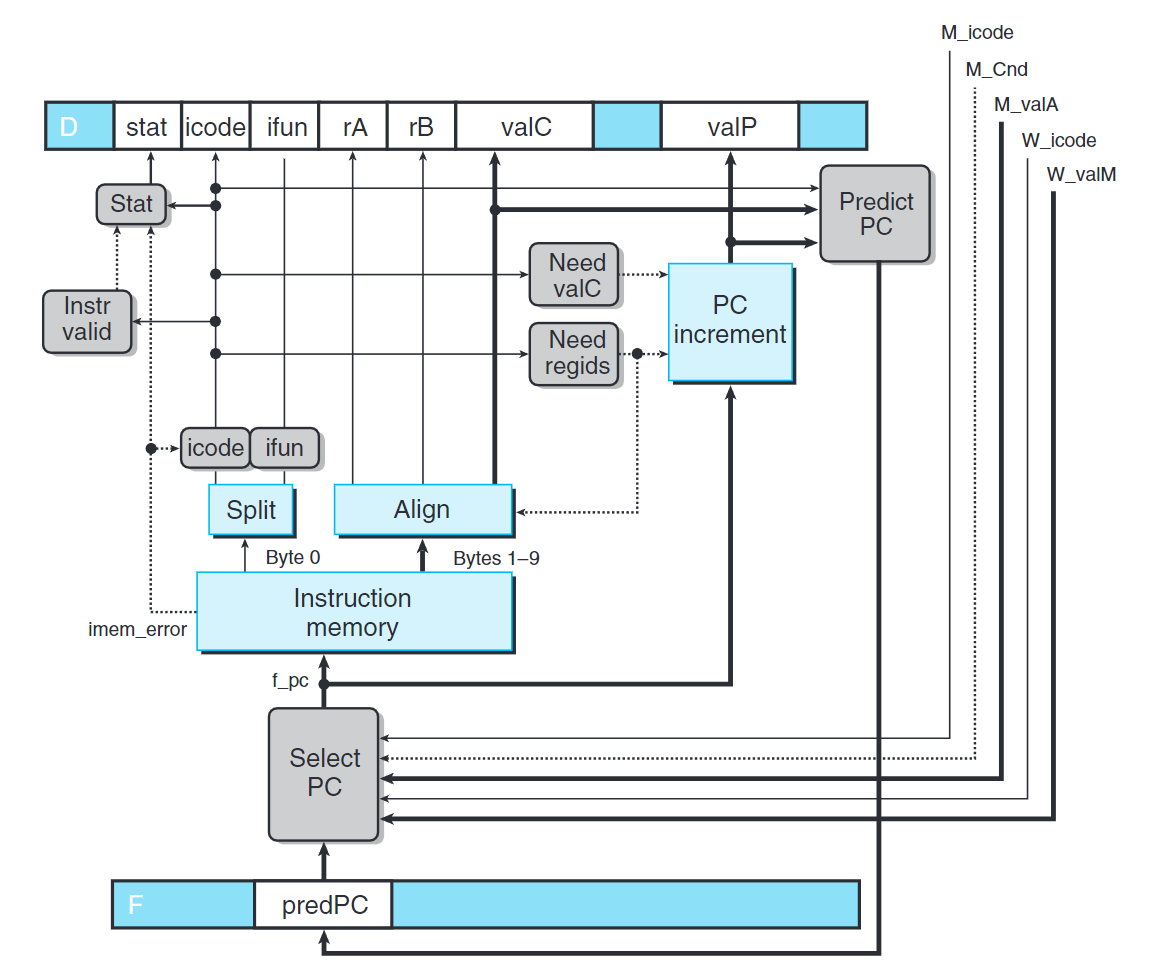
PC選擇邏輯從三個源中選擇:
- 對分支預測錯誤的指令進入訪存階段時,從
M_valA讀出該指令的valP。 - 當
ret指令進入寫回階段時,從W_valM讀出返回地址。 - 使用
F_predPC。
1 | word f_pc = [ |
若為函數調用或跳轉,選擇valC,否則選擇valP。
1 | word f_predPC = [ |
與SEQ不同,我們需要將指令狀態的計算分為兩個部分。
取指階段檢測:指令地址越界引起的內存錯誤、非法指令、halt指令。
訪存階段檢測:非法數據地址。
1 | word f_stat = [ |
譯碼階段和寫回階段
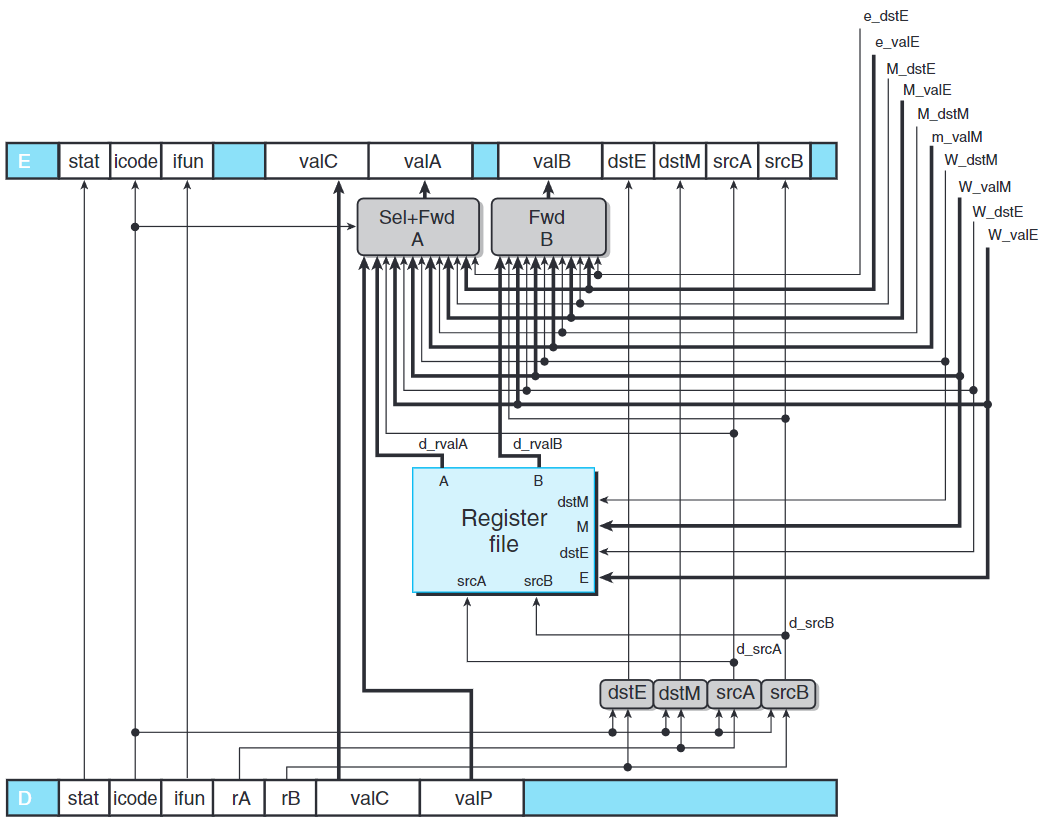
上圖示PIPE譯碼和寫回階段的詳細說明。
注意,傳給寫端口的寄存器ID來自於寫回階段(W_dstE和W_dstM),而不是來自譯碼階段。
1 | word d_dstE = [ |
| 數據字 | 寄存器ID | 源描述 |
|---|---|---|
e_valE |
e_dstE |
ALU輸出 |
m_valM |
M_dstM |
內存輸出 |
M_valE |
M_dstE |
訪存階段對端口E未進行的寫 |
W_valM |
W_dstM |
寫回階段對端口M未進行的寫 |
W_valE |
W_dstE |
寫回階段對端口E未進行的寫 |
1 | word d_valA = [ |
處理轉發邏輯的優先級是十分重要的。
我們應給予處於較早流水線階段中的轉發源更高的優先級,因為其等同於設置該寄存器的最近的指令。
上圖說明了這種例子,如果使用處於較晚流水線階段的轉發,會造成程序執行結果錯誤。
1 | word d_valB = [ |
流水線寄存器W保存著最近完成指令的狀態,所以使用該值計算整個處理器的狀態。
注意,當寫回階段有氣泡應視為正常操作。
1 | word Stat = [ |
練習題
4.32
注意,遇到popq需要暫停一個週期。此時,會讀取增加後的%rsp,與慣例不同。
4.33
1 | irmovq $5, %rdx |
連續兩個nop導致rrmovq在譯碼階段時,pop處於寫回階段。若給予錯誤的轉發優先級,會導致讀取增加後的%rsp。

執行階段
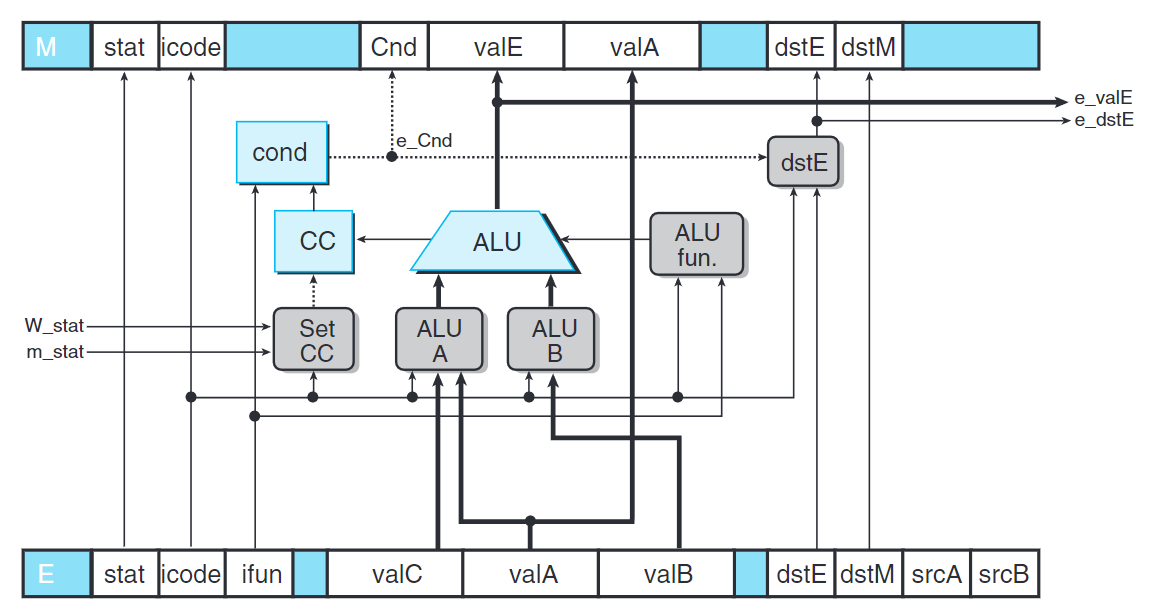
上圖是PIPE執行階段的邏輯,這些硬件單元與SEQ中的相同,使用的信號做些微的重命名。
我們注意e_valE與e_dstE轉發到譯碼階段。
且SetCC接收兩個信號W_Stat與m_Stat以更新條件碼。
練習題
4.35
若使用E_dstE代替d_valA中的e_dstE會導致無法判斷條件數據傳送的失敗,導致轉發了不應該被轉發的值。
訪存階段
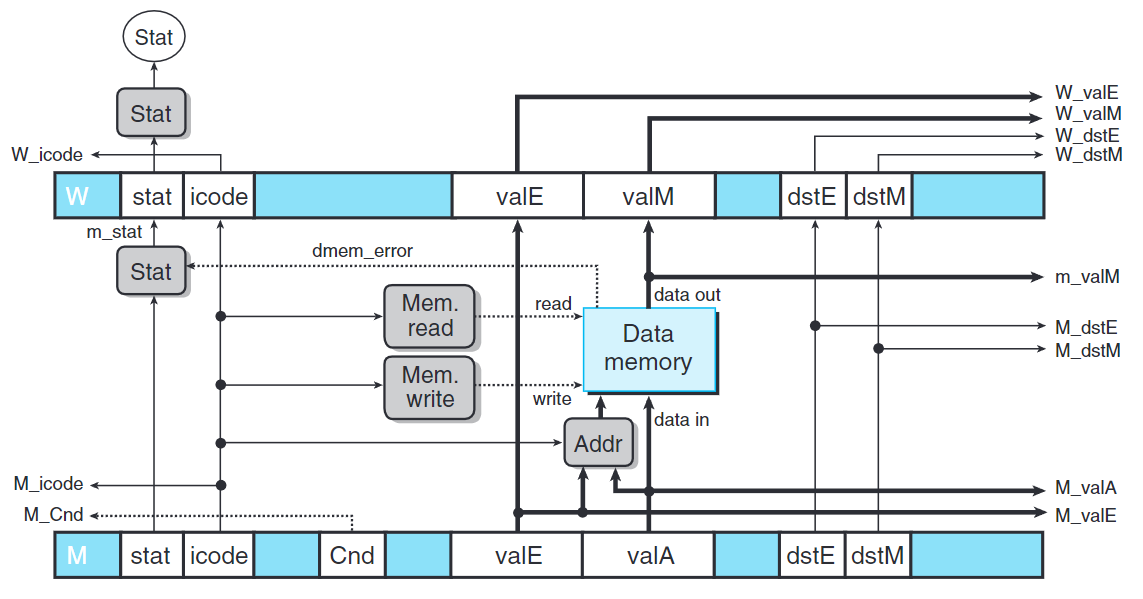
相比於SEQ,PIPE缺少了Mem.data塊。在SEQ中,此塊用來對valP和valA做選擇的。但在PIPE中被Sel+Fwd A取代。
練習題
4.36
1 | word m_stat = [ |
流水線控制邏輯
在此我們要創建流水線控制邏輯,處理數據轉發和分支預測不能處理的4種情況。
- 加載/使用冒險:從內存讀出值後,下一條指令需要立即使用該值 -> 暫停一周期
ret指令- 分支預測錯誤
- 異常
特殊情況的處理
當遇到加載/使用冒險,即mrmovq或popq指令,並處於執行階段時,且需要該目的寄存器的指令正處於譯碼階段,我們需要將第二條指令阻塞在譯碼階段,並在下一個週期往執行階段插入一個氣泡。之後,轉發邏輯會解決這個數據冒險。
對於ret,我們需要暫停三個時鐘週期(第四個周期恢復)。直到ret經過訪存階段,讀出返回地址。
當分支預測錯誤時,即跳轉指令到達執行階段檢測到預測錯誤,在下一個時鐘週期往執行和譯碼階段插入氣泡,取消兩個錯誤的指令。
對於異常指令,我們需要滿足ISA規定的行為,即前面所有指令結束前,後面的指令不能影響程序狀態。
這些因素會導致滿足行為較麻煩:
- 異常在兩個不同階段(取指、訪存)被發現
- 狀態在三個不同階段(執行、訪存和寫回)被更新
當異常指令到達訪存階段時,我們採取以下措施防止後續指令更改程序員可見狀態:
- 禁止執行階段的指令設置條件碼
- 向訪存階段插入氣泡,以禁止向內存中寫入
- 當寫回階段有異常指令時,暫停寫回階段,因而暫停了流水線
發現特殊控制條件
| 條件 | 觸發條件 | |
|---|---|---|
ret指令 |
$IRET \in { D_icode, E_icode, M_{icode} }$ | |
| 加載/使用冒險 | $E_icode \in { IMRMOVL, IPOPL } \ \&\& \ E_dstM \in { d_srcA, d_{srcB} }$ | |
| 分支預測錯誤 | $E_icode ==IJXX \ \&\& \ !e_Cnd$ | |
| 異常 | $m_stat \in { SARD, SINS, SHLT } \ \ | \ W_stat \in { SADR, SINS, SHLT }$ |
流水線控制機制
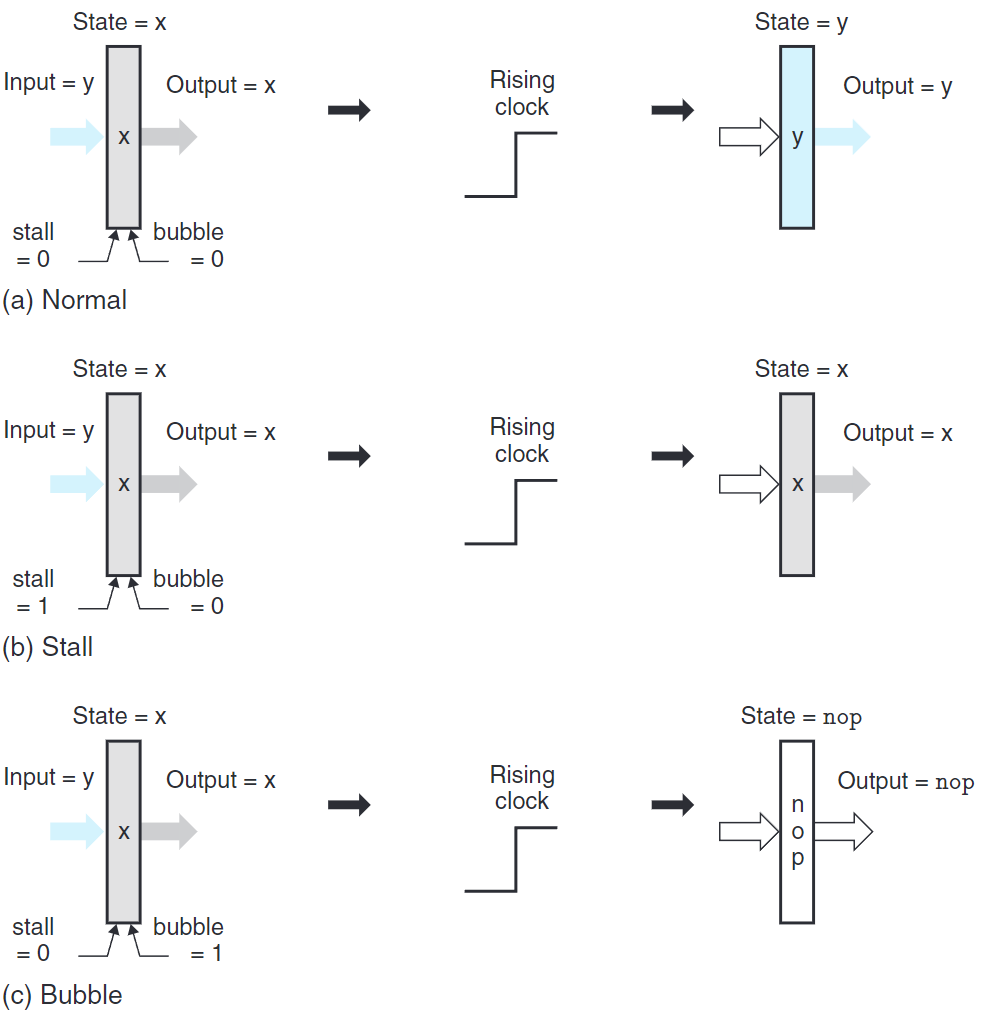
假設每個流水線寄存器有兩個控制輸入:暫停(stall)和氣泡(bubble),兩個信號同時為1視為錯誤。
當暫停信號設置為1時,禁止更新狀態,寄存器保持原值。使得將某個指令阻塞在某個階段。
當氣泡信號設置為1時,寄存器狀態設置成固定的復位配置(reset configuration),得到等效為nop的狀態。
復位配置的0、1模式由流水線寄存器的字段集合決定。例如,往流水線寄存器D插入氣泡,我們需要將icode設為INOP。想要往流水線寄存器E插入氣泡,則需要將icode設為INOP,並將dstE, dstM, srcA, srcB設為常數RNONE。
| 條件(流水寄存器) | F | D | E | M | W |
|---|---|---|---|---|---|
ret |
暫停 | 氣泡(此時檢測到預測錯誤) | 正常(ret處於譯碼階段) |
正常(運行到此時已插入三個氣泡) | 正常 |
| 加載/使用冒險 | 暫停 | 暫停 | 氣泡(此時檢測到預測錯誤) | 正常(指令處於執行階段) | 正常 |
| 分支預測錯誤 | 正常 | 氣泡 | 氣泡(此時檢測到預測錯誤) | 正常(指令處於訪存階段) | 正常 |
控制條件的組合
目前為止,我們假設一個時鐘周期內最多只出現一個特殊情況。現在來考慮同時處裡多個特殊情況。
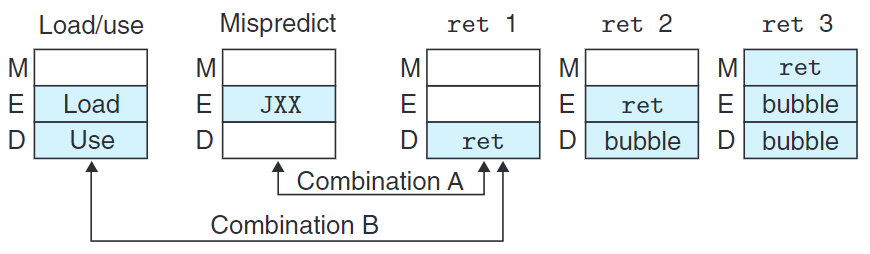
上圖為特殊控制條件的流水線狀態,圖中的一對Combination可能同時出現。
當出現Combination A時,如下處理。
| 條件(流水寄存器) | F | D | E | M | W |
|---|---|---|---|---|---|
ret |
暫停 | 氣泡(此時檢測到預測錯誤) | 正常(ret處於譯碼階段) |
正常(運行到此時已插入三個氣泡) | 正常 |
| 分支預測錯誤 | 正常 | 氣泡 | 氣泡(此時檢測到預測錯誤) | 正常(指令處於訪存階段) | 正常 |
| 組合 | 暫停 | 氣泡 | 氣泡 | 正常 | 正常 |
當出現Combination B時,如下處理。
| 條件(流水寄存器) | F | D | E | M | W |
|---|---|---|---|---|---|
ret |
暫停 | 氣泡(此時檢測到預測錯誤) | 正常(ret處於譯碼階段) |
正常(運行到此時已插入三個氣泡) | 正常 |
| 加載/使用冒險 | 暫停 | 暫停 | 氣泡(此時檢測到預測錯誤) | 正常(指令處於執行階段) | 正常 |
| 組合 | 暫停 | 暫停+氣泡 | 氣泡 | 正常 | 正常 |
| 期望 | 暫停 | 暫停 | 氣泡 | 正常 | 正常 |
控制邏輯實現
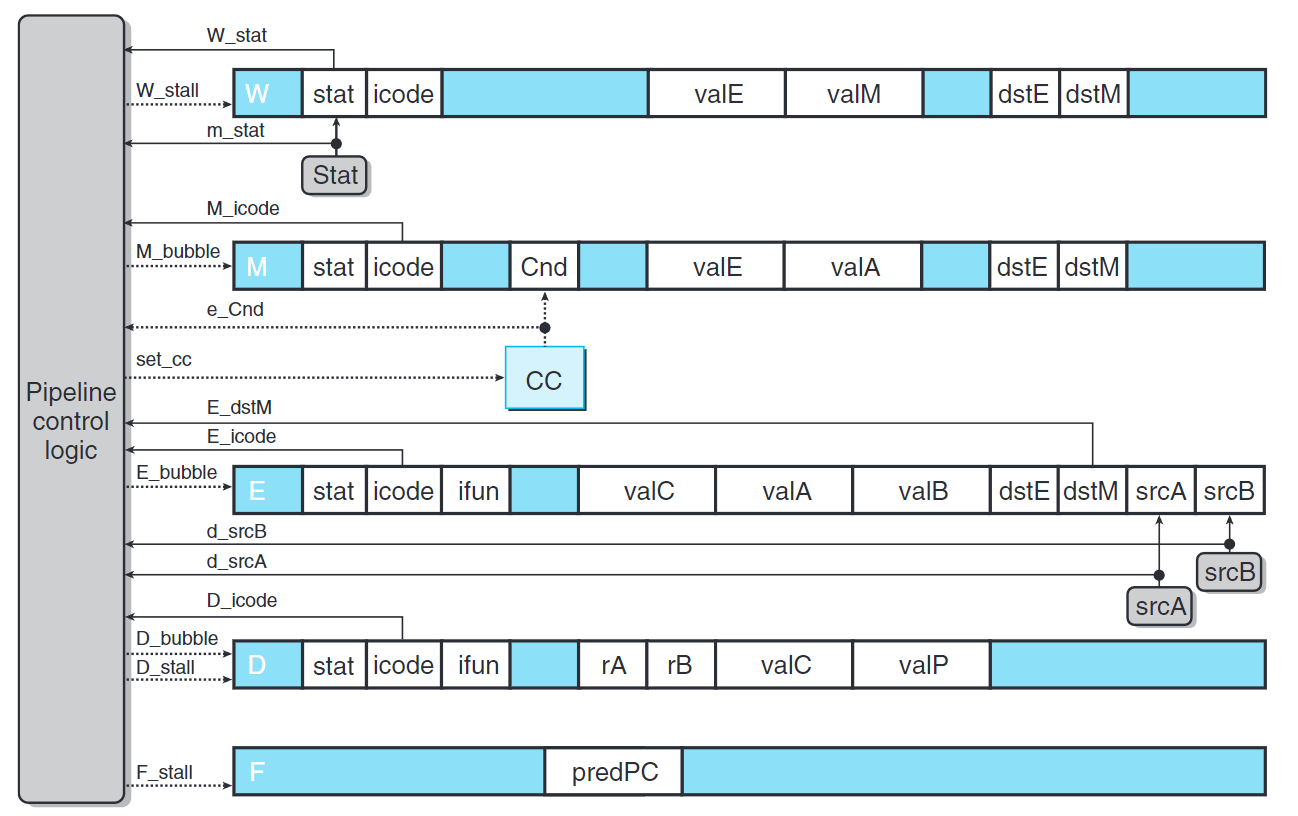
上圖是流水線控制邏輯的整題結構。
結合此部分各表格,我們可以寫出各個流水線控制信號的HCL描述。
1 | bool F_stall = |
1 | bool D_stall = |
1 | bool D_bubble = |
1 | bool E_bubble = |
1 | bool set_cc = |
1 | bool M_bubble = |
W_stall只要檢查W_stat因為如果m_stat為真,該指令會在訪存階段暫停,而無法進入寫回階段。
1 | bool W_stall = |
性能分析
我們使用CPI(Cycle Per Instruction,每指令周期數) 來評估整體性能。時間單位是時間週期,而不是微微秒。
若某階段共處理了$C{i}$條指令和$C{b}$個氣泡,則處理器大約需要$C{i}+C{b}$個時鐘週期來執行$C_{i}$條指令。
我們如下定義CPI:
即,$1.0$加上處罰項$\frac{C{b}}{C{i}}$,該項表明一條指令平均要插入多少個氣泡。
若令加載/使用冒險插入的氣泡平均數為$lp(load \ penalty,加載處罰)$,預測分支錯誤插入的氣泡平均數為$mp(\text{mispredicted branch penalty},預測錯誤分支處罰)$,ret指令插入的氣泡平均數為$rp(\text{return penlaty},返回處罰)$。
則CPI可表示為:
練習題
4.43-4.44
略






![[GAMES 101] Rasterization 筆記](/pictures/SAO.jpg)


