此實驗Part C極難,Part A 與 Part B全都是為Part C所準備而較為簡單。最終我的Part C得分為:39.3/60.0,所以我的解析也僅供參考,而非最佳解。期間我也參考過其他大佬的文章,但所有代碼相關改動都是由我一個個嘗試出來的。如果各位大佬有更好的優化方法歡迎指正!
Part A
跟隨實驗手冊,此部分我們需要在sim/misc目錄下完成。
此部分我們需要編寫三個Y86-64程序,模擬example.c中三個函數的行為。
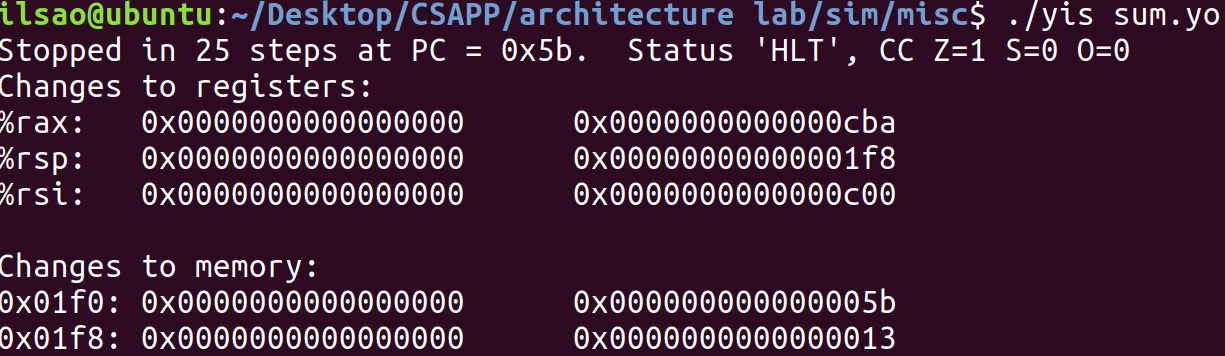
sum.ys:迭代求鏈表各項和
example.c對鏈表的實現:
1 2 3 4
typedefstructELE { long val; structELE *next; } *list_ptr;
example.c對這個函數的實現:
1 2 3 4 5 6 7 8 9 10
/* sum_list - Sum the elements of a linked list */ longsum_list(list_ptr ls) { long val = 0; while (ls) { val += ls->val; ls = ls->next; } return val; }
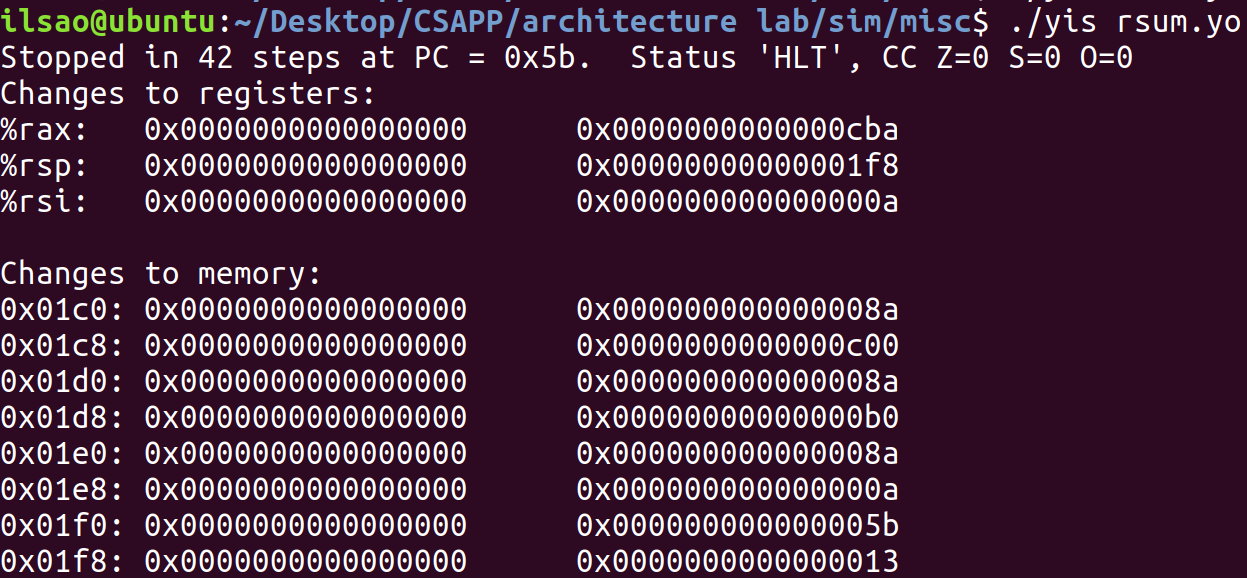
/* rsum_list - Recursive version of sum_list */ longrsum_list(list_ptr ls) { if (!ls) return0; else { long val = ls->val; long rest = rsum_list(ls->next); return val + rest; } }
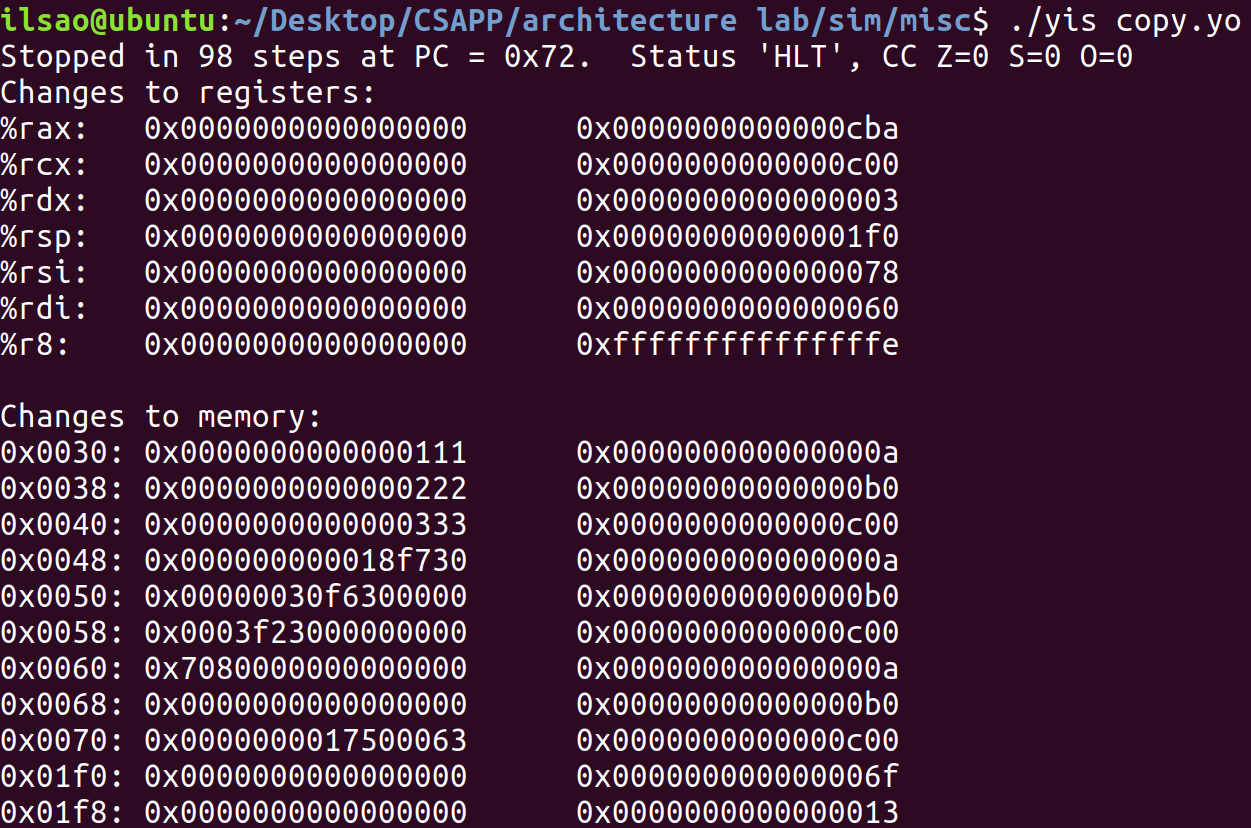
/* copy_block - Copy src to dest and return xor checksum of src */ longcopy_block(long *src, long *dest, long len) { long result = 0; while (len > 0) { long val = *src++; *dest++ = val; result ^= val; len--; } return result; }
ilsao@ubuntu:~/Desktop/CSAPP/architecture lab/sim/y86-code$ cd ../ptest; make SIM=../seq/ssim ./optest.pl -s ../seq/ssim Simulating with ../seq/ssim All 49 ISA Checks Succeed ./jtest.pl -s ../seq/ssim Simulating with ../seq/ssim All 64 ISA Checks Succeed ./ctest.pl -s ../seq/ssim Simulating with ../seq/ssim All 22 ISA Checks Succeed ./htest.pl -s ../seq/ssim Simulating with ../seq/ssim All 600 ISA Checks Succeed
測試iaddq指令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
ilsao@ubuntu:~/Desktop/CSAPP/architecture lab/sim/ptest$ cd ../ptest; make SIM=../seq/ssim -i ./optest.pl -s ../seq/ssim Simulating with ../seq/ssim All 49 ISA Checks Succeed ./jtest.pl -s ../seq/ssim Simulating with ../seq/ssim All 64 ISA Checks Succeed ./ctest.pl -s ../seq/ssim Simulating with ../seq/ssim All 22 ISA Checks Succeed ./htest.pl -s ../seq/ssim Simulating with ../seq/ssim All 600 ISA Checks Succeed
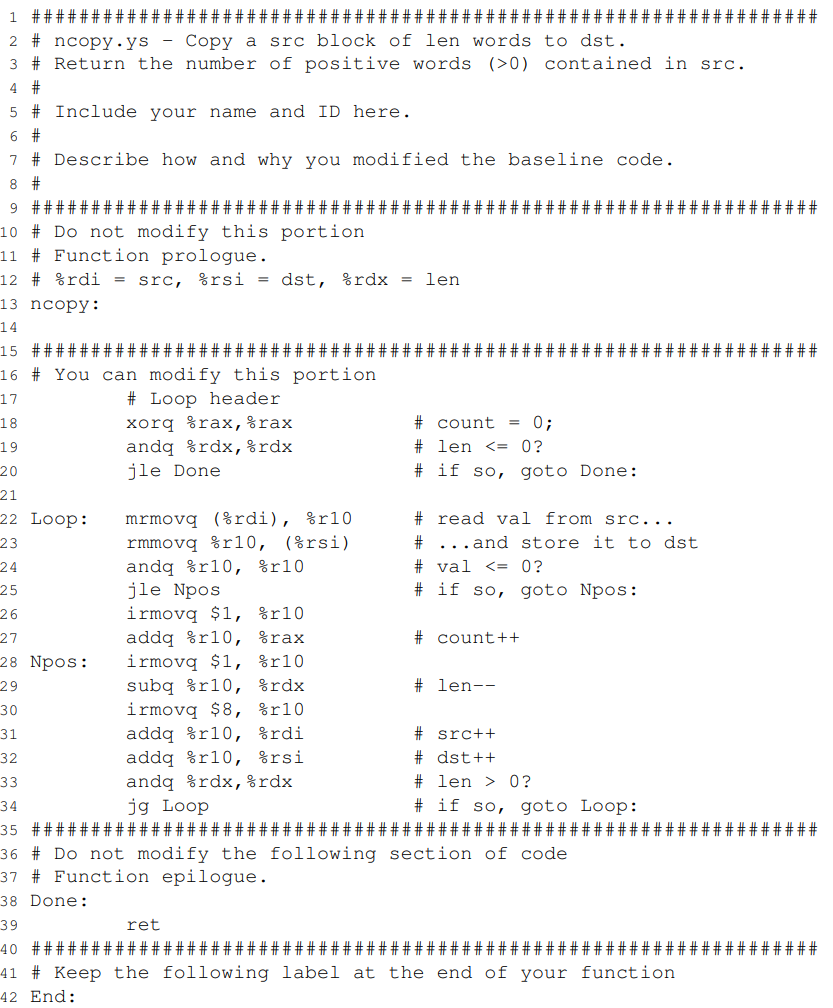
#/* $begin ncopy-ys */ ################################################################## # ncopy.ys - Copy a src block of len words to dst. # Return the number of positive words(>0) contained in src. # # author: asciibase64 # # Describe how and why you modified the baseline code. # ################################################################## # Do not modify this portion # Function prologue. # %rdi = src, %rsi = dst, %rdx = len ncopy:
################################################################## # You can modify this portion # Loop header xorq %rax,%rax # count = 0; andq %rdx,%rdx # len <= 0? jle Done # if so, goto Done:
Loop: mrmovq (%rdi), %r10 # read val from src... rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Npos # if so, goto Npos: iaddq $1, %rax # count++ Npos: iaddq $-1, %rdx # len-- iaddq $8, %rdi # src++ iaddq $8, %rsi # dst++ andq %rdx,%rdx # len > 0? jg Loop # if so, goto Loop: ################################################################## # Do not modify the following section of code # Function epilogue. Done: ret ################################################################## # Keep the following label at the end of your function End: #/* $end ncopy-ys */
Loop: mrmovq (%rdi), %r10 # read val from src... rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Loop2 # if so, goto Loop2: iaddq $1, %rax # count++ Loop2: mrmovq 8(%rdi), %r10 # read val from src... rmmovq %r10, 8(%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Npos # if so, goto Npos: iaddq $1, %rax # count++ Npos: iaddq $-2, %rdx # len -= 2; iaddq $16, %rdi # src++ iaddq $16, %rsi # dst++ Check: andq %rdx,%rdx # len > 0? jg Loop # if so, goto Loop: LastCheck: andq %rdx, %rdx # len != 0? jne Done # if so, goto Done: mrmovq (%rdi), %r10 # read val from src... rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Npos # if so, goto Npos: iaddq $1, %rax # count++
Loop: mrmovq (%rdi), %r10 # read val from src... rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Loop2 # if so, goto Loop2: iaddq $1, %rax # count++ Loop2: mrmovq 8(%rdi), %r10 # read val from src... rmmovq %r10, 8(%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Loop3 # if so, goto Loop3: iaddq $1, %rax # count++ Loop3: mrmovq 16(%rdi), %r10 # read val from src... rmmovq %r10, 16(%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Npos # if so, goto Npos: iaddq $1, %rax # count++ Npos: iaddq $24, %rdi # src++ iaddq $24, %rsi # dst++ Check: subq %rcx,%rdx # len > min (len -= min at the same time)? jg Loop # if so, goto Loop:
BeforeLastCheck: addq %rcx, %rdx # Because our Check do len -= min at the same time, we have to add min back jmp LastCheck
LastLoop: mrmovq (%rdi), %r10 # read val from src... rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle LastNpos # if so, goto LastNpos: iaddq $1, %rax # count++ LastNpos: iaddq $-1, %rdx # len-- iaddq $8, %rdi # src++ iaddq $8, %rsi # dst++ LastCheck: andq %rdx,%rdx # len > 0? jg LastLoop # if so, goto LastLoop:
測試CPE:
1 2
./benchmark.pl Average CPE 9.97
我們嘗試繼續進行循環展開,直到找到最優解。
1 2 3 4 5 6
2*1 Average CPE 10.64 3*1 Average CPE 9.97 4*1 Average CPE 9.79 5*1 Average CPE 9.73 6*1 Average CPE 9.73 7*1 Average CPE 9.76
Loop: mrmovq (%rdi), %r10 # read val from src... rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Loop2 # if so, goto Loop2: iaddq $1, %rax # count++ Loop2: mrmovq 8(%rdi), %r10 # read val from src... rmmovq %r10, 8(%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Loop3 # if so, goto Loop3: iaddq $1, %rax # count++ Loop3: mrmovq 16(%rdi), %r10 # read val from src... rmmovq %r10, 16(%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Loop4 # if so, goto Loop4: iaddq $1, %rax # count++ Loop4: mrmovq 24(%rdi), %r10 # read val from src... rmmovq %r10, 24(%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Loop5 # if so, goto Loop5: iaddq $1, %rax # count++ Loop5: mrmovq 32(%rdi), %r10 # read val from src... rmmovq %r10, 32(%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Npos # if so, goto Npos: iaddq $1, %rax # count++ Npos: iaddq $40, %rdi # src++ iaddq $40, %rsi # dst++ Check: subq %rcx,%rdx # len >= min (len -= min at the same time)? jge Loop # if so, goto Loop:
BeforeLastCheck: addq %rcx, %rdx # Because our Check do len -= min at the same time, we have to add min back jmp LastCheck
LastLoop: mrmovq (%rdi), %r10 # read val from src... rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle LastNpos # if so, goto LastNpos: iaddq $1, %rax # count++ LastNpos: iaddq $-1, %rdx # len-- iaddq $8, %rdi # src++ iaddq $8, %rsi # dst++ LastCheck: andq %rdx,%rdx # len > 0? jg LastLoop # if so, goto LastLoop:
減少流水線冒險
加載/使用冒險
加載/使用冒險發生在遇到mrmovq/popq指令後,下一條指令需要立即使用從內存中的讀取值時。
要減少這種冒險,我們可以簡單的改變Loop之間的交互。
1 2 3 4 5 6 7 8 9 10 11 12
Loop: mrmovq (%rdi), %r10 # read val from src... rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Loop2 # if so, goto Loop2: iaddq $1, %rax # count++ Loop2: mrmovq 8(%rdi), %r10 # read val from src... rmmovq %r10, 8(%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Loop3 # if so, goto Loop3: iaddq $1, %rax # count++
Loop: mrmovq (%rdi), %r10 # read val from src... mrmovq 8(%rdi), %r11 #read val from src for Loop2 rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Loop2 # if so, goto Loop2: iaddq $1, %rax # count++ Loop2: mrmovq 16(%rdi), %r10 # read val from src for Loop3 rmmovq %r11, 8(%rsi) # use the val from Loop and store it to dst andq %r11, %r11 # val <= 0? jle Loop3 # if so, goto Loop3: iaddq $1, %rax # count++ Loop3: mrmovq 24(%rdi), %r11 # read val from src... rmmovq %r10, 16(%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Loop4 # if so, goto Loop4: iaddq $1, %rax # count++ Loop4: mrmovq 32(%rdi), %r10 # read val from src... rmmovq %r11, 24(%rsi) # ...and store it to dst andq %r11, %r11 # val <= 0? jle Loop5 # if so, goto Loop5: iaddq $1, %rax # count++ Loop5: rmmovq %r10, 32(%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Npos # if so, goto Npos: iaddq $1, %rax # count++ Npos: iaddq $40, %rdi # src++ iaddq $40, %rsi # dst++ Check: subq %rcx,%rdx # len >= min (len -= min at the same time)? jge Loop # if so, goto Loop:
BeforeLastCheck: addq %rcx, %rdx # Because our Check do len -= min at the same time, we have to add min back jmp LastCheck
LastLoop: mrmovq (%rdi), %r10 # read val from src... rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle LastNpos # if so, goto LastNpos: iaddq $1, %rax # count++ LastNpos: iaddq $-1, %rdx # len-- iaddq $8, %rdi # src++ iaddq $8, %rsi # dst++ LastCheck: andq %rdx,%rdx # len > 0? jg LastLoop # if so, goto LastLoop:
Loop: mrmovq (%rdi), %r10 # read val from src... mrmovq 8(%rdi), %r11 #read val from src for Loop2 rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Loop2 # if so, goto Loop2: iaddq $1, %rax # count++ Loop2: mrmovq 16(%rdi), %r10 # read val from src for Loop3 rmmovq %r11, 8(%rsi) # use the val from Loop and store it to dst andq %r11, %r11 # val <= 0? jle Loop3 # if so, goto Loop3: iaddq $1, %rax # count++ Loop3: mrmovq 24(%rdi), %r11 # read val from src... rmmovq %r10, 16(%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Loop4 # if so, goto Loop4: iaddq $1, %rax # count++ Loop4: mrmovq 32(%rdi), %r10 # read val from src... rmmovq %r11, 24(%rsi) # ...and store it to dst andq %r11, %r11 # val <= 0? jle Loop5 # if so, goto Loop5: iaddq $1, %rax # count++ Loop5: rmmovq %r10, 32(%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Npos # if so, goto Npos: iaddq $1, %rax # count++ Npos: iaddq $40, %rdi # src++ iaddq $40, %rsi # dst++ Check: subq %rcx,%rdx # len > min (len -= min at the same time)? jge Loop # if so, goto Loop:
BeforeLastCheck: addq %rcx, %rdx # Because our Check do len -= min at the same time, we have to add 5 back jmp FirstLastCheck
LastLoop: mrmovq (%rdi), %r10 # read val from src... iaddq $-1, %rdx # len-- rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle LastCheck # if so, goto LastCheck: iaddq $1, %rax # count++ LastCheck: iaddq $8, %rdi # src++ iaddq $8, %rsi # dst++ andq %rdx, %rdx jle Done LastLoop2: mrmovq (%rdi), %r10 # read val from src... iaddq $-1, %rdx # len-- rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle LastCheck2 # if so, goto LastCheck2: iaddq $1, %rax # count++ LastCheck2: iaddq $8, %rdi # src++ iaddq $8, %rsi # dst++ andq %rdx, %rdx jle Done LastLoop3: mrmovq (%rdi), %r10 # read val from src... iaddq $-1, %rdx # len-- rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle LastCheck3 # if so, goto LastCheck3: iaddq $1, %rax # count++ LastCheck3: iaddq $8, %rdi # src++ iaddq $8, %rsi # dst++ andq %rdx, %rdx jle Done LastLoop4: mrmovq (%rdi), %r10 # read val from src... iaddq $-1, %rdx # len-- rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle LastCheck4 # if so, goto LastCheck4: iaddq $1, %rax # count++ LastCheck4: iaddq $8, %rdi # src++ iaddq $8, %rsi # dst++ jmp Done








![[GAMES 101] Rasterization 筆記](/pictures/SAO.jpg)


